Cloud passthrough proxy
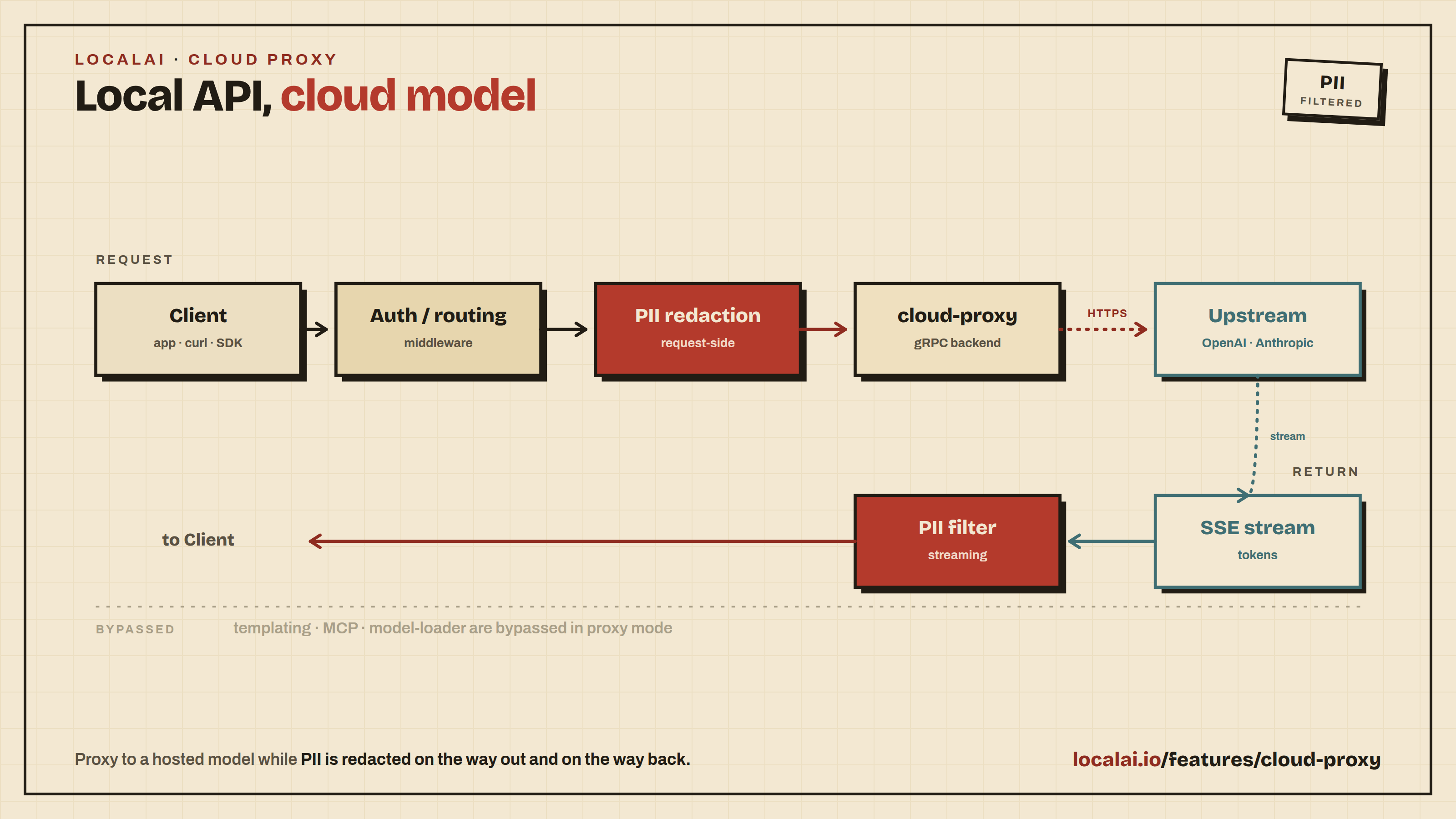
LocalAI can forward chat-completion and Anthropic Messages requests to an
external provider instead of running them through the local gRPC backend
pipeline. Configure a model with backend: cloud-proxy and a proxy.upstream_url,
and LocalAI bypasses templating, MCP injection, and the local model loader
entirely - the upstream sees the body the client sent (with only the top-level
model field optionally rewritten).
The streaming PII filter still runs over the upstream’s SSE stream, so cloud egress remains subject to the same redaction rules a local model would apply.
When to use this
- Mix local and cloud models in the same LocalAI instance - clients hit one endpoint, LocalAI dispatches per model.
- Apply LocalAI’s auth, usage tracking, and PII redaction to cloud traffic before the body leaves the network.
- Use the intelligent router to send small or simple prompts to a local model and complex ones to Claude or GPT-4o.
How it works
- Request hits LocalAI on
/v1/chat/completions(OpenAI-shaped) or/v1/messages(Anthropic-shaped). - The standard auth and routing middleware runs.
- Per-model PII redaction runs request-side as it would for any model.
- The handler detects the
cloud-proxybackend in passthrough mode and loads the cloud-proxy gRPC backend, which owns the outbound HTTP. - The backend POSTs the body to
proxy.upstream_urlwith provider-aware authentication, then streams the SSE response back to core. - The streaming PII filter rewrites per-token text in flight; the upstream’s event names and metadata pass through unchanged.
Passthrough mode is wire-format-faithful - it does not translate request shapes between providers. A client posting an OpenAI-shaped body to an Anthropic upstream will get a confused upstream. Use the matching wire format, or switch to translate mode (below).
Configuration
The cloud-proxy backend has one knob - the provider it should authenticate against - and two modes:
proxy.mode | What it does | When to use |
|---|---|---|
passthrough (default) | Forwards the request body verbatim to upstream_url. Client must speak the upstream’s wire format. | Same wire format on both ends. |
translate | Backend converts internal proto to the upstream’s wire format. Client can speak OpenAI-shaped requests to an Anthropic upstream, etc. | Cross-format adaptation. |
proxy.provider selects the auth scheme and (in translate mode) the wire
format. Supported values: openai, anthropic.
API keys are loaded from either an environment variable (api_key_env) or a
file (api_key_file). The key never appears in the config file or the admin
UI; pick whichever fits your secret-management setup.
OpenAI passthrough
Then start LocalAI with the API key in the environment:
Clients hit http://localhost:8080/v1/chat/completions with "model": "gpt-4o-proxy"
and the request lands on OpenAI’s API.
Anthropic passthrough
Anthropic clients hit http://localhost:8080/v1/messages with
"model": "claude-sonnet-proxy".
Other OpenAI-compatible providers
Most third-party providers (Together, Groq, DeepInfra, OpenRouter, …) speak
the OpenAI chat-completions wire format. Use provider: openai with the
provider’s URL and API key:
Translate mode
In translate mode the cloud-proxy backend converts LocalAI’s internal proto to the provider’s wire format. This lets a client speak one shape (e.g. OpenAI Chat Completions) against an upstream that expects another (e.g. Anthropic Messages).
Translate mode currently routes only pure-text completions - tool calls,
image blocks, and per-request usage tokens are dropped through the
internal Predict() signature. Use passthrough mode when your clients need
the upstream’s full feature set.
Loading secrets from a file
api_key_file is an alternative to api_key_env when your secret manager
mounts keys as files (e.g. Kubernetes secrets, Docker secrets, Vault Agent):
The file is read at backend load time and trimmed of surrounding whitespace.
api_key_env and api_key_file are mutually exclusive.
Combining with the intelligent router
A router model can spread traffic across local and cloud candidates. The score classifier reads the policy descriptions and routes per request:
The router rewrites input.Model to the chosen candidate; per-model PII,
ACLs, and the cloud-proxy fork all run against the resolved target.
See Middleware: PII filtering and intelligent routing for the full router and PII-filter reference.
Limitations
- Passthrough does no wire-shape translation. Use
mode: translate(with the constraints documented above) or send requests that match the upstream’s format. - No output-side PII for non-streaming responses. Streaming responses are filtered in flight; buffered responses pass through verbatim. Request-side PII covers both.
- No retry or backoff. Transient upstream failures bubble up to the client
as
502 Bad Gateway. - No request shape validation. If the upstream rejects the body, its error envelope is forwarded to the client unchanged.
Operational notes
- Cloud-proxy backends load like any other gRPC backend - they consume one process per loaded model and appear in the backend management view, but they hold no GPU memory.
- Usage stats and the trace log capture cloud-proxy requests like any other
request. Token counts come from the upstream’s
usagefield when present. - Set
request_timeout_secondsdefensively - a hung upstream otherwise ties up an HTTP handler until the client disconnects.