Distributed Mode
Distributed mode enables horizontal scaling of LocalAI across multiple machines using PostgreSQL for state and node registry, and NATS for real-time coordination. Unlike the P2P/federation approach, distributed mode is designed for production deployments and Kubernetes environments where you need centralized management, health monitoring, and deterministic routing.
Note
Distributed mode requires authentication enabled with a PostgreSQL database — SQLite is not supported. This is because the node registry, job store, and other distributed state are stored in PostgreSQL tables.
Architecture Overview
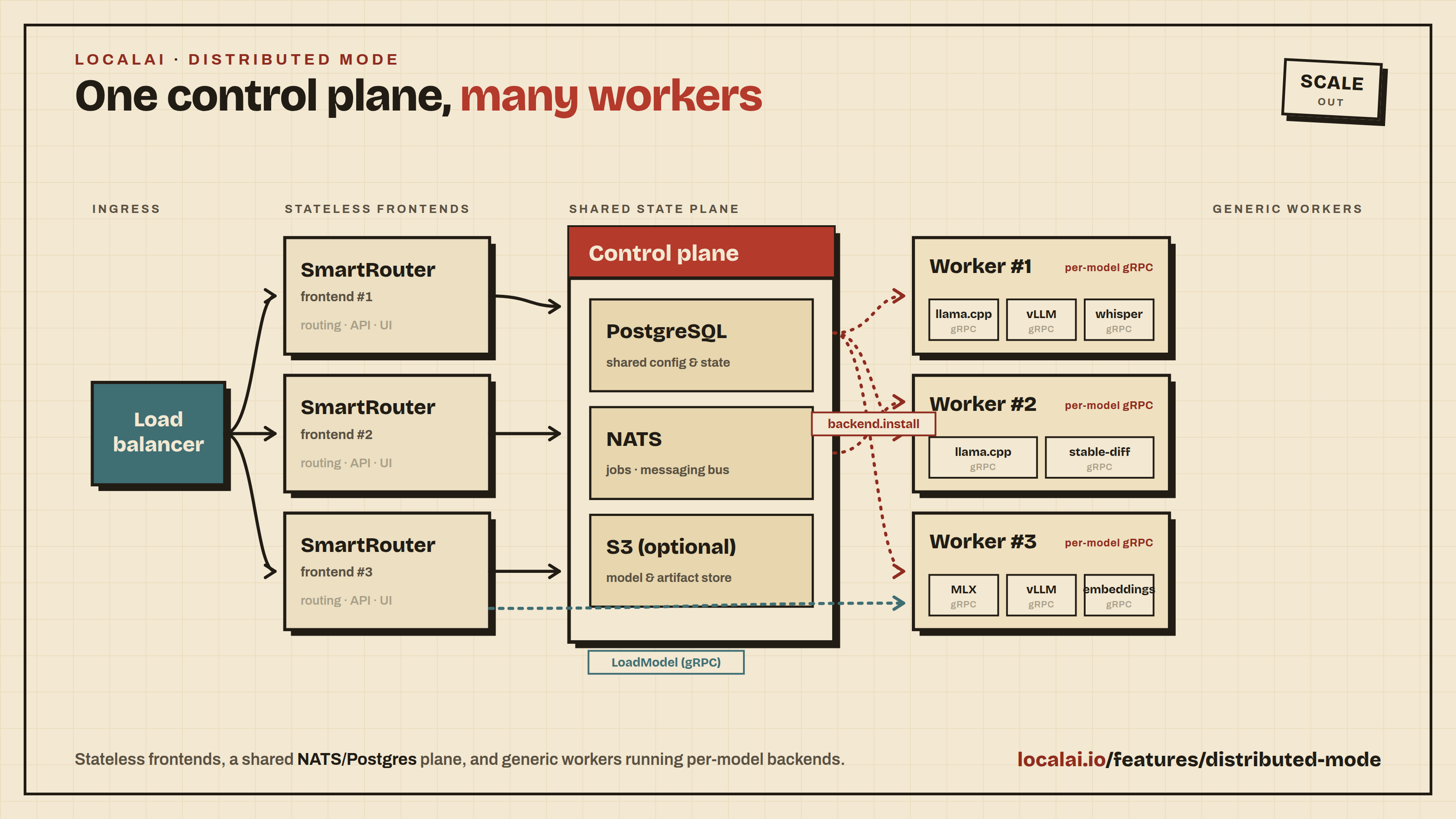
Frontends are stateless LocalAI instances that receive API requests and route them to worker nodes via the SmartRouter. All frontends share state through PostgreSQL and coordinate via NATS.
Workers are generic processes that self-register with a frontend. They don’t have a fixed backend type — the SmartRouter dynamically installs the required backend via NATS backend.install events when a model request arrives.
Scheduling Algorithm
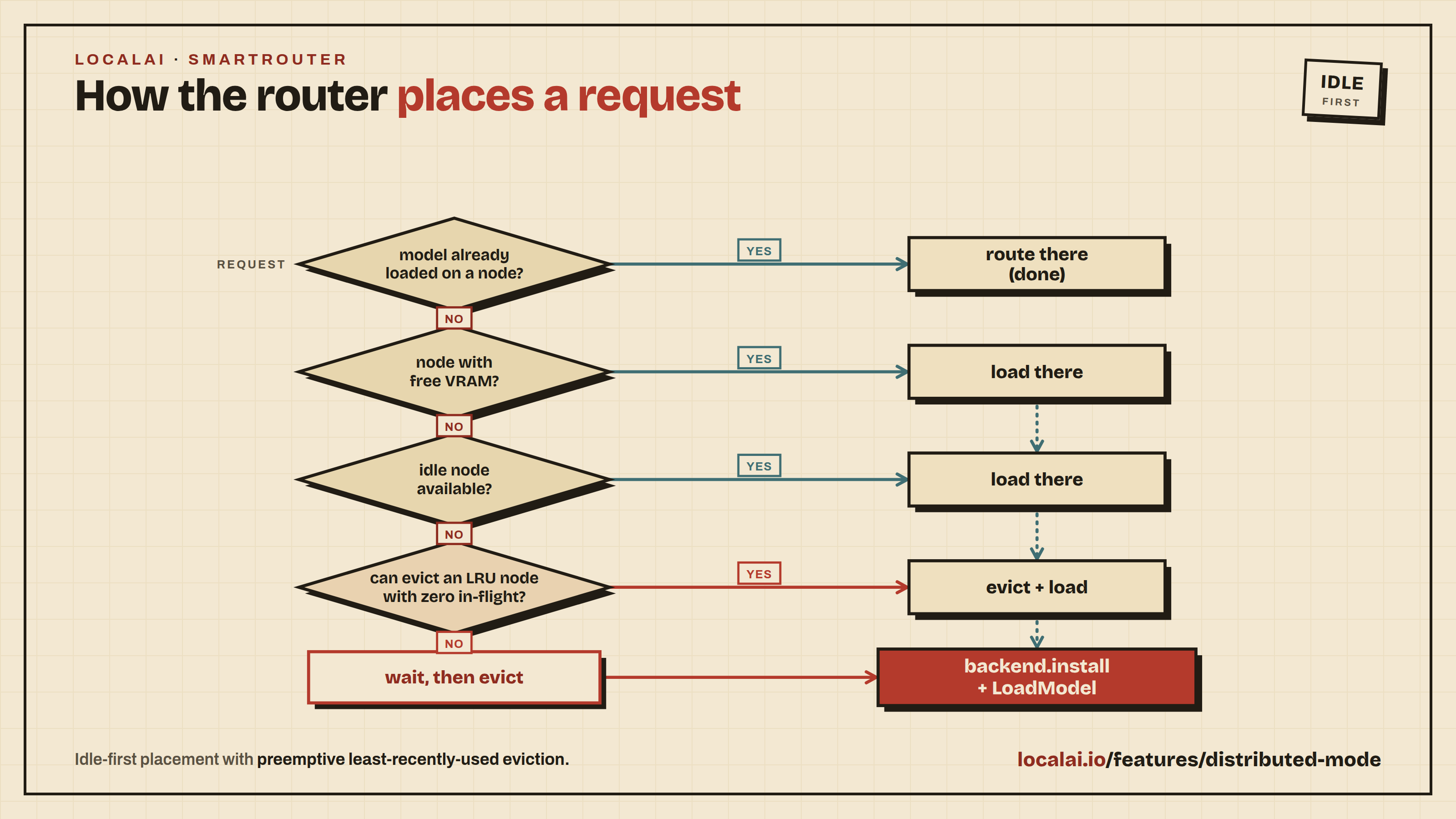
The SmartRouter uses idle-first scheduling with preemptive eviction:
- If the model is already loaded on a node → use it (per-model gRPC address)
- If no node has the model → prefer nodes with enough free VRAM
- Fall back to idle nodes (zero models), then least-loaded nodes
- If no node has capacity → evict the least-recently-used model with zero in-flight requests to free a node
- If all models are busy → wait (with timeout) for a model to become idle, then evict
- Send
backend.installNATS event with backend name + model ID → worker starts a new gRPC process on a dynamic port - SmartRouter calls gRPC
LoadModelon the model-specific port, records in DB
Each model gets its own gRPC backend process, so a single worker can serve multiple models simultaneously (e.g., a chat model and an embedding model).
Prerequisites
- PostgreSQL (with pgvector extension recommended for RAG) — used for node registry, job store, auth, and shared state
- NATS server — used for real-time backend lifecycle events and file staging
- All services must be on the same network (or reachable via configured URLs)
Quick Start with Docker Compose
The easiest way to try distributed mode locally is with the provided Docker Compose file:
This starts PostgreSQL, NATS, a LocalAI frontend, and one worker node. When you send an inference request, the SmartRouter automatically installs the needed backend on the worker and loads the model. See the file for details on adding GPU support, shared volumes, and additional workers.
Tip
Use docker-compose.distributed.yaml for quick local testing. For production, deploy PostgreSQL and NATS as managed services and run frontends/workers on separate hosts.
Frontend Configuration
The frontend is a standard LocalAI instance with distributed mode enabled. These flags are added to the local-ai run command:
| Flag | Env Var | Default | Description |
|---|---|---|---|
--distributed | LOCALAI_DISTRIBUTED | false | Enable distributed mode |
--instance-id | LOCALAI_INSTANCE_ID | auto UUID | Unique instance ID for this frontend |
--nats-url | LOCALAI_NATS_URL | (required) | NATS server URL (e.g., nats://localhost:4222) |
--registration-token | LOCALAI_REGISTRATION_TOKEN | (empty) | Token that workers must provide to register |
--registration-require-auth | LOCALAI_REGISTRATION_REQUIRE_AUTH | false | Fail startup when distributed mode is enabled but the registration token is empty (node endpoints and worker file-transfer would otherwise be unauthenticated) |
--distributed-require-auth | LOCALAI_DISTRIBUTED_REQUIRE_AUTH | false | Umbrella switch. Implies both --nats-require-auth and --registration-require-auth — one knob to lock down the NATS bus and the registration/file-transfer layer. Set this in production instead of the two granular flags. |
--auto-approve-nodes | LOCALAI_AUTO_APPROVE_NODES | false | Auto-approve new worker nodes (skip admin approval) |
--distributed-shared-models | LOCALAI_DISTRIBUTED_SHARED_MODELS | false | Assert that every node mounts the same models directory at the same path (a shared volume). When true, the router skips file staging entirely and workers load models directly from the shared path instead of re-downloading them. See Shared models directory. |
--auth | LOCALAI_AUTH | false | Must be true for distributed mode |
--auth-database-url | LOCALAI_AUTH_DATABASE_URL | (required) | PostgreSQL connection URL |
--backend-install-timeout | LOCALAI_NATS_BACKEND_INSTALL_TIMEOUT | 15m | How long the frontend waits for a worker to acknowledge a backend install before considering the request stalled. Raise it when workers pull large backend images over slow links. If a worker takes longer than this, the operation shows as “still installing in background” in the admin UI and clears once the worker finishes. |
--backend-upgrade-timeout | LOCALAI_NATS_BACKEND_UPGRADE_TIMEOUT | 15m | Same as the install timeout, applied to backend upgrades (force-reinstall). |
--expose-node-header | LOCALAI_EXPOSE_NODE_HEADER | false | When enabled, inference responses carry an X-LocalAI-Node header with the ID of the worker node that served the request. Coverage spans the OpenAI-compatible endpoints (chat completions, completions, embeddings, audio transcriptions, audio speech / TTS, image generations, image inpainting), the Jina rerank endpoint (/v1/rerank), the VAD endpoints (/v1/vad, /vad), and the Anthropic Messages (/v1/messages) and Ollama (/api/chat, /api/generate, /api/embed) shims. Useful for debugging, observability and load-balancer attribution. Off by default: the node ID reveals internal cluster topology and should not be exposed on a public endpoint. Best-effort: under heavy concurrency for the same model across multiple replicas, the header may reflect a recent routing decision rather than this exact request’s. Acceptable for observability and debugging. |
NATS JWT authentication (recommended for production)
By default, NATS connections are anonymous: any client that can reach port 4222 may publish control-plane subjects such as nodes.<id>.backend.install. Enable JWT auth to scope workers to their own node subjects and give the frontend a dedicated service credential.
| Flag | Env Var | Description |
|---|---|---|
--nats-account-seed | LOCALAI_NATS_ACCOUNT_SEED | Account signing seed (SU...). The frontend mints a per-node user JWT at registration (nats_jwt in the register response). |
--nats-service-jwt | LOCALAI_NATS_SERVICE_JWT | User JWT for the frontend (and optional fallback for agent workers) to publish install/upgrade and related subjects. |
--nats-service-seed | LOCALAI_NATS_SERVICE_SEED | User signing seed (SU...) paired with the service JWT. |
--nats-worker-jwt-ttl | LOCALAI_NATS_WORKER_JWT_TTL | Lifetime of minted worker JWTs (default 24h). |
--nats-require-auth | LOCALAI_NATS_REQUIRE_AUTH | Fail startup if JWT credentials are missing when distributed mode is enabled. |
NATS TLS / mTLS (optional)
Use tls:// in --nats-url / LOCALAI_NATS_URL for encrypted transport. When the server uses a private CA or requires client certificates, set:
| Flag | Env Var | Description |
|---|---|---|
--nats-tls-ca | LOCALAI_NATS_TLS_CA | PEM file to verify the NATS server (private CA) |
--nats-tls-cert | LOCALAI_NATS_TLS_CERT | Client certificate for NATS mTLS |
--nats-tls-key | LOCALAI_NATS_TLS_KEY | Client private key (required with --nats-tls-cert) |
The same env vars apply to backend workers and local-ai agent-worker. If the server cert is already trusted by the OS, tls:// alone is enough.
Worker register response (when minting is enabled and the node is approved):
Workers connect with that JWT and seed automatically (shown once; store securely). Override with LOCALAI_NATS_JWT / LOCALAI_NATS_USER_SEED if needed. Set LOCALAI_NATS_REQUIRE_AUTH=true on workers when the bus requires credentials.
When LOCALAI_NATS_REQUIRE_AUTH=true and no static credentials are provided, a worker that registers while still pending admin approval keeps re-registering (with backoff) until an admin approves it and the frontend mints its JWT — it does not start unauthenticated. This retry is bounded: if the node is never approved (or no credentials are minted) after a large number of attempts, the worker exits non-zero so the failure is visible (a crash-looping or failed worker) rather than hanging silently. Minted worker JWTs are also refreshed automatically before they expire (the worker re-registers at ~75% of the JWT lifetime), so long-running workers survive past LOCALAI_NATS_WORKER_JWT_TTL; the NATS connection picks up the new JWT on its next reconnect. If refresh fails persistently, the worker exits (to restart and re-acquire) rather than drifting toward an expired, unrenewable JWT. Statically configured (LOCALAI_NATS_JWT) and service (LOCALAI_NATS_SERVICE_JWT) credentials are used as-is and not refreshed.
Generate operator/account material with scripts/nats-auth-setup.sh (requires nsc). Configure the NATS server with account resolver JWTs before enabling LOCALAI_NATS_REQUIRE_AUTH.
Note
LOCALAI_AUTH (HTTP users/sessions) and NATS JWTs are separate: end-user API keys do not connect to NATS. HTTP registration still uses LOCALAI_REGISTRATION_TOKEN.
Optional: S3 Object Storage
For multi-host deployments where workers don’t share a filesystem, S3-compatible storage enables distributed file transfer (model files, configs):
| Flag | Env Var | Default | Description |
|---|---|---|---|
--storage-url | LOCALAI_STORAGE_URL | (empty) | S3 endpoint URL (e.g., http://minio:9000) |
--storage-bucket | LOCALAI_STORAGE_BUCKET | localai | S3 bucket name |
--storage-region | LOCALAI_STORAGE_REGION | us-east-1 | S3 region |
--storage-access-key | LOCALAI_STORAGE_ACCESS_KEY | (empty) | S3 access key |
--storage-secret-key | LOCALAI_STORAGE_SECRET_KEY | (empty) | S3 secret key |
When S3 is not configured, model files are transferred directly from the frontend to workers via HTTP — no shared filesystem needed. Each worker runs a small HTTP file transfer server alongside the gRPC backend process. This is the default and works out of the box.
For high-throughput or very large model files, S3 can be more efficient since it avoids streaming through the frontend.
Shared models directory
If every node (frontend and workers) mounts the same models directory at the same path - for example a shared volume or network filesystem, as shown in the “Shared Volume Mode” section of docker-compose.distributed.yaml - the model files are already present on each worker at their canonical path. In that case staging is wasted work: it copies files that already exist into a per-model subdirectory the worker then loads from, which shows up as a re-download of a model you already have.
Set LOCALAI_DISTRIBUTED_SHARED_MODELS=true (or --distributed-shared-models) on the frontend to skip staging entirely. The router then leaves the model’s absolute paths untouched and the worker loads them directly from the shared volume.
This flag is a contract you assert: all nodes must mount identical paths. Leave it off (the default) when workers have independent models directories - the frontend stages files to them over HTTP (or S3) as described above.
Warning
The worker HTTP file transfer server is authenticated by LOCALAI_REGISTRATION_TOKEN. If the token is empty, the server fails open — anyone who can reach the port gets read/write access to the worker’s models/staging/data directories (a remote model-poisoning / exfiltration vector). The worker logs a loud warning at startup in this case. Always set LOCALAI_REGISTRATION_TOKEN in distributed mode, and set LOCALAI_DISTRIBUTED_REQUIRE_AUTH=true (frontend and workers) to make a missing token or missing NATS credentials a hard startup error rather than a silent fail-open. Firewall the file-transfer port (gRPC base − 1) so only the frontend can reach it.
Watching Backend Installs
While a worker downloads a backend, the admin Operations Bar at the top of the UI shows real-time progress: current file, downloaded/total bytes, and percentage. This works the same as single-node mode.
When an install targets more than one worker, an N nodes chevron appears on the operation row. Click it to expand a per-node breakdown, with one row per worker showing:
- A status pill: Queued (gray), Downloading (blue), Worker busy (yellow), Done (green), or Failed (red).
- The file currently being downloaded with current/total bytes and percentage.
- A thin per-node progress bar.
- Any error returned by the worker.
The yellow Worker busy pill means the worker took longer than
--backend-install-timeout to acknowledge but is most likely still
working in the background. The admin UI clears it as soon as the worker
finishes; no action is required from the operator.
If a worker is running an older LocalAI release that does not report progress, its row in the breakdown will still show terminal status (queued / done / failed / worker busy) but no per-file progress.
Worker Configuration
Workers are started with the worker subcommand. Each worker is generic — it doesn’t need a backend type at startup:
| Flag | Env Var | Default | Description |
|---|---|---|---|
--addr | LOCALAI_SERVE_ADDR | 0.0.0.0:50051 | gRPC listen address |
--advertise-addr | LOCALAI_ADVERTISE_ADDR | (auto) | Address the frontend uses to reach this node (see below) |
--http-addr | LOCALAI_HTTP_ADDR | gRPC port - 1 | HTTP file transfer server bind address |
--advertise-http-addr | LOCALAI_ADVERTISE_HTTP_ADDR | (auto) | HTTP address the frontend uses for file transfer |
--register-to | LOCALAI_REGISTER_TO | (required) | Frontend URL for self-registration |
--node-name | LOCALAI_NODE_NAME | hostname | Human-readable node name |
--registration-token | LOCALAI_REGISTRATION_TOKEN | (empty) | Token to authenticate with the frontend |
--registration-require-auth | LOCALAI_REGISTRATION_REQUIRE_AUTH | false | Refuse to start the HTTP file-transfer server when no registration token is set (it would otherwise fail open) |
--distributed-require-auth | LOCALAI_DISTRIBUTED_REQUIRE_AUTH | false | Umbrella switch implying both --registration-require-auth and --nats-require-auth |
--heartbeat-interval | LOCALAI_HEARTBEAT_INTERVAL | 10s | Interval between heartbeat pings |
--nats-url | LOCALAI_NATS_URL | (required) | NATS URL for backend installation and file staging |
--nats-jwt | LOCALAI_NATS_JWT | (empty) | Optional override for the nats_jwt returned at registration |
--nats-user-seed | LOCALAI_NATS_USER_SEED | (empty) | Optional override for nats_user_seed from registration |
--nats-require-auth | LOCALAI_NATS_REQUIRE_AUTH | false | Require NATS JWT+seed (from registration or env) |
--nats-tls-ca | LOCALAI_NATS_TLS_CA | (empty) | PEM file for NATS server CA |
--nats-tls-cert | LOCALAI_NATS_TLS_CERT | (empty) | Client certificate for NATS mTLS |
--nats-tls-key | LOCALAI_NATS_TLS_KEY | (empty) | Client private key for NATS mTLS |
--backends-path | LOCALAI_BACKENDS_PATH | ./backends | Path to backend binaries |
--models-path | LOCALAI_MODELS_PATH | ./models | Path to model files |
Tip
Advertise address: The --addr flag is the local bind address for gRPC. The --advertise-addr is the address the frontend stores and uses to reach the worker via gRPC. If not set, the worker auto-derives it by replacing 0.0.0.0 with the OS hostname (which in Docker is the container ID, resolvable via Docker DNS). Set --advertise-addr explicitly when the auto-detected hostname is not routable from the frontend (e.g., in Kubernetes, use the pod’s service DNS name).
HTTP file transfer: Each worker also runs a small HTTP server for file transfer (model files, configs). By default it listens on the gRPC base port - 1 (e.g., if gRPC base is 50051, HTTP is on 50050). gRPC ports grow upward from the base port as additional models are loaded. Set --advertise-http-addr if the auto-detected address is not routable from the frontend.
Worker Address Configuration
The simplest way to configure a worker’s network address is with a single variable:
| Variable | Description |
|---|---|
LOCALAI_ADDR | Reachable address of this worker (host:port). The port is used as the base for gRPC backend processes, and port-1 for the HTTP file transfer server. |
Example:
For advanced networking scenarios (NAT, load balancers, separate gRPC/HTTP ports), the following override variables are available:
| Variable | Description | Default |
|---|---|---|
LOCALAI_SERVE_ADDR | gRPC base port bind address | 0.0.0.0:50051 |
LOCALAI_HTTP_ADDR | HTTP file transfer bind address | 0.0.0.0:{gRPC port - 1} |
LOCALAI_ADVERTISE_ADDR | Public gRPC address (if different from LOCALAI_ADDR) | Derived from LOCALAI_ADDR |
LOCALAI_ADVERTISE_HTTP_ADDR | Public HTTP address (if different from gRPC host) | Derived from advertise host + HTTP port |
NVIDIA GPU support
When running workers in a container, two runtime settings affect how VRAM usage is reported back to the frontend:
NVIDIA_DRIVER_CAPABILITIESmust includeutility. Without it, the NVML library (and thereforenvidia-smi) is not available inside the container. CUDA compute still works, but the worker cannot query free VRAM and the Nodes page will show the node as fully used. SetNVIDIA_DRIVER_CAPABILITIES=compute,utility(or, with the NVIDIA CDI runtime, listcapabilities: [gpu, utility]on the device reservation).Run the container with
init: true(ordocker run --init). The worker process becomes PID 1 in the container and cannot reap zombies on its own. Without an init,nvidia-smicalls can fail intermittently withwaitid: no child processes, which briefly clears free-VRAM metrics.
Unified memory devices (Jetson, DGX Spark / GB10, Thor): these SoCs
share one physical RAM between CPU and GPU. LocalAI detects them via
/sys/devices/soc0/family and /sys/devices/soc0/soc_id (no nvidia-smi
required) and reports system-RAM figures as VRAM. Free VRAM therefore tracks
MemAvailable in /proc/meminfo.
Node Labels
Workers can declare labels at startup for scheduling constraints:
| Variable | Description | Example |
|---|---|---|
LOCALAI_NODE_LABELS | Comma-separated key=value labels | tier=premium,gpu=a100,zone=us-east |
Labels can also be managed via the admin API (see Label Management API below).
The system automatically applies hardware-detected labels on registration:
gpu.vendor– GPU vendor (nvidia, amd, intel, vulkan)gpu.vram– GPU VRAM bucket (8GB, 16GB, 24GB, 48GB, 80GB+)node.name– The node’s registered name
How Workers Operate
Workers start as generic processes with no backend installed. When the SmartRouter needs to load a model on a worker, it sends a NATS backend.install event with the backend name and model ID. The worker:
- Installs the backend from the gallery (if not already installed)
- Starts a new gRPC backend process on a dynamic port (each model gets its own process)
- Replies with the allocated gRPC address
- The SmartRouter calls
LoadModelvia direct gRPC to that address
Workers can run multiple models concurrently — each model gets its own gRPC process on a separate port. For example, an embedding model on port 50051 and a chat model on port 50052 can run simultaneously on the same worker.
When the SmartRouter needs to free capacity, it can unload models with zero in-flight requests without affecting other models on the same worker.
Node Management API
The API is split into two prefixes with distinct auth:
/api/node/ — Node self-service
Used by workers themselves (registration, heartbeat, etc.). Authenticated via the registration token, exempt from global auth.
| Method | Path | Description |
|---|---|---|
POST | /api/node/register | Register a new worker |
POST | /api/node/:id/heartbeat | Update heartbeat timestamp |
POST | /api/node/:id/drain | Mark self as draining |
GET | /api/node/:id/models | Query own loaded models |
DELETE | /api/node/:id | Deregister self |
/api/nodes/ — Admin management
Used by the WebUI and admin API consumers. Requires admin authentication.
| Method | Path | Description |
|---|---|---|
GET | /api/nodes | List all registered workers |
GET | /api/nodes/:id | Get a single worker by ID |
GET | /api/nodes/:id/models | List models loaded on a worker |
DELETE | /api/nodes/:id | Admin-delete a worker |
POST | /api/nodes/:id/drain | Admin-drain a worker |
POST | /api/nodes/:id/approve | Approve a pending worker node |
POST | /api/nodes/:id/backends/install | Install a backend on a worker |
POST | /api/nodes/:id/backends/delete | Delete a backend from a worker |
POST | /api/nodes/:id/models/unload | Unload a model from a worker |
POST | /api/nodes/:id/models/delete | Delete model files from a worker |
The Nodes page in the React WebUI provides a visual overview of all registered workers, their statuses, and loaded models. The page opens with a one-line cluster pulse summarising node health and an attention callout that surfaces nodes needing action (for example pending approvals). Below that, a roster of node panels lists each worker with its inline model chips (no expand click needed), filtered by an All / Backend / Agent segmented control. Selecting a panel opens a dedicated node detail page at /app/nodes/:id with per-node metrics, models, and backend actions. Model scheduling lives on its own Scheduling page (separate nav item), not as a tab on the Nodes page.
Node Approval
By default, new worker nodes start in pending status and must be approved by an admin before they can receive traffic. This prevents unknown machines from joining the cluster.
To approve a pending node via the API:
The Nodes page in the WebUI also shows pending nodes with an Approve button.
To skip manual approval and let nodes join immediately, set --auto-approve-nodes (or LOCALAI_AUTO_APPROVE_NODES=true) on the frontend. This is convenient for development and trusted environments.
Node Statuses
| Status | Meaning |
|---|---|
pending | Node registered but waiting for admin approval (when --auto-approve-nodes is false) |
healthy | Node is active and responding to heartbeats |
unhealthy | Node has missed heartbeats beyond the threshold (detected by the HealthMonitor) |
offline | Node is temporarily offline (graceful shutdown or stale heartbeat). The node row is preserved so re-registration restores the previous approval status without requiring re-approval |
draining | Node is shutting down gracefully — no new requests are routed to it, existing in-flight requests are allowed to complete |
Agent Workers
Agent workers are dedicated processes for executing agent chats and MCP CI jobs. Unlike backend workers (which run gRPC model inference), agent workers use cogito to orchestrate multi-step conversations with tool calls.
Agent workers:
- Execute agent chat messages dispatched via NATS
- Run MCP CI jobs (with access to MCP servers via docker)
- Handle MCP tool discovery and execution requests from the frontend
- Get auto-provisioned API keys during registration for calling the inference API
In the docker-compose setup, the agent worker mounts the Docker socket so it can run MCP stdio servers (e.g., docker run commands):
MCP in Distributed Mode
MCP servers configured in model configs work in distributed mode. The frontend routes MCP operations through NATS to agent workers:
- MCP discovery (
GET /v1/mcp/servers/:model): routed to agent workers which create sessions and return server info - MCP tool execution (during
/v1/chat/completions): tool calls are routed to agent workers via NATS request-reply - MCP CI jobs: executed entirely on agent workers with access to docker for stdio-based MCP servers
vLLM Multi-Node (Data-Parallel)
A single vLLM model can span multiple GPU nodes via data parallelism: the head node serves the OpenAI API and runs the local DP ranks, follower nodes run vanilla vllm serve --headless and speak ZMQ directly to the head. LocalAI’s role is starting the follower processes and surfacing them in the admin UI; the cross-rank tensor traffic is vLLM’s own.
This mode is operator-launched — the head config and each follower’s invocation must agree on the topology (data_parallel_size, data_parallel_size_local, data_parallel_address, data_parallel_rpc_port). The SmartRouter does not place follower ranks automatically.
Head node configuration
The head runs the existing single-node vLLM gRPC backend. Set engine_args to publish the DP topology vLLM expects:
The head will start its 2 local ranks, listen on 10.0.0.1:32100, and wait for the remaining 2 ranks to handshake.
Follower nodes
Each follower runs local-ai p2p-worker vllm with matching topology, an explicit start rank, and the head’s address:
--register-to is optional but recommended — it makes the follower visible in the admin UI as an agent-type node tagged with node.role=vllm-follower. Without it the worker just runs vLLM and exits silently when vLLM does. The role label discourages SmartRouter from placing other models on the follower; pair it with model selectors like {"!node.role":"vllm-follower"} if you also run regular LocalAI models on the same fleet.
Worked example: 2-node Kimi-K2.6 deployment
Two A100 nodes (10.0.0.1, 10.0.0.2), 8 GPUs total, data_parallel_size=8 with 4 ranks per node:
A curl http://10.0.0.1:8080/v1/chat/completions ... against the head will then dispatch across all 8 ranks.
Intel Arc / XPU notes
vLLM XPU supports DP (vllm/platforms/xpu.py:198 handles world_size_across_dp > 1; ranks bind to xpu:{local_rank} in xpu_worker.py:62, with xccl as the collective backend). Each rank still needs a distinct discrete GPU — the iGPU on a hybrid host is not a viable second device.
Older XE-HPG GPUs (e.g. Arc A770) need to bypass the cutlass attention path:
docker-compose.vllm-multinode.intel.yaml at the repo root is the Intel equivalent of docker-compose.vllm-multinode.yaml — uses /dev/dri passthrough, ZE_AFFINITY_MASK to pin each rank to one device, and latest-gpu-intel images. Run via ./tests/e2e/vllm-multinode/smoke.sh --intel.
Caveats
- Tensor parallel within a node only. vLLM v1 does not support TP across nodes; combine
tensor_parallel_size(within a node, viaengine_args) withdata_parallel_size(across nodes). - Followers don’t host LocalAI gRPC. The follower process is vanilla vLLM, so
/api/backend-logs/<modelId>does not stream follower output. Usejournalctl/kubectl logs/ compose logs for the follower’s stderr. - Network reachability. The head’s
data_parallel_rpc_portplus a range of ZMQ ports (typicallydata_parallel_rpc_port..+N) must be reachable from every follower. Open them in your firewall / security group. - Topology must match exactly. A mismatch in
--data-parallel-sizebetween head and any follower will hang the handshake. Check the head’s vLLM logs forwaiting for N DP ranksif startup stalls.
ds4 Layer-Split Distributed Inference
The ds4 backend (DeepSeek V4 Flash) supports layer-parallel distributed inference: a single model that is too large for one machine is split by transformer layer across several machines. Each machine must have the GGUF present locally, but loads only its own slice of the layers. This lets you run a model whose weights exceed any single host’s memory.
This is not routed through the SmartRouter: it is a model-internal split, configured manually (Phase 1). It is unrelated to the NATS/PostgreSQL distributed mode described above.
Topology
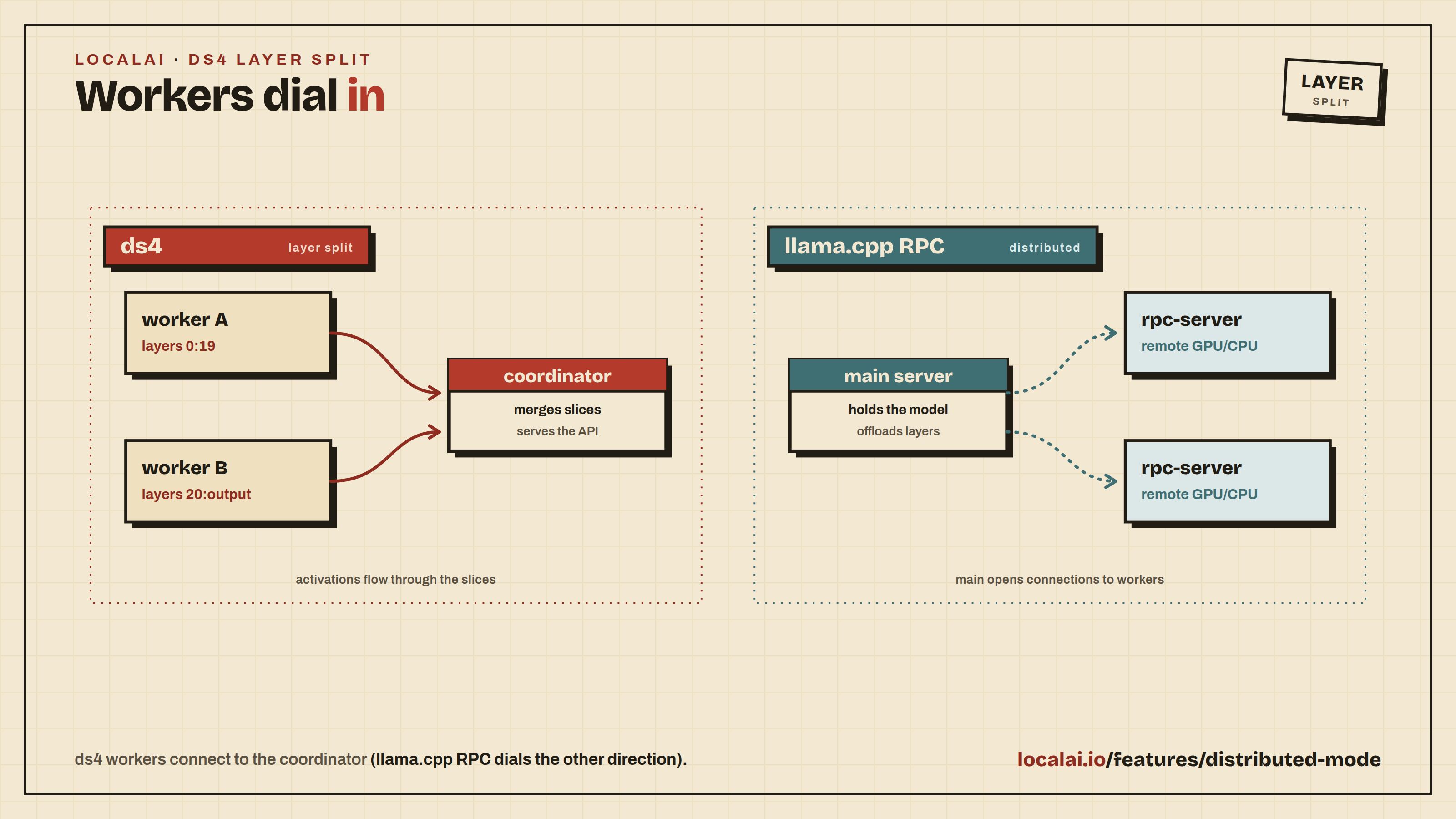
ds4 uses a coordinator/worker split:
- The coordinator owns tokenization, sampling, the prompt, and a low layer range (e.g.
0:19). It is LocalAI’s ds4 backend and listens on a host/port. Workers dial into it. - One or more workers own higher layer ranges (e.g.
20:output). Each worker loads only its slice and dials the coordinator to register the range it can serve. The last worker normally owns the output head. - Activations flow through the connected slices and back to the coordinator. The route is “ready” only once the coordinator plus all connected workers cover every layer.
This dial direction is the inverse of the llama.cpp RPC model, where the main server dials out to a list of rpc-server workers. With ds4 the workers dial in to the coordinator.
Coordinator setup
The coordinator is a normal LocalAI ds4 model whose YAML carries distributed options::
| Option | Meaning |
|---|---|
ds4_role:coordinator | Enables distributed coordinator mode. Without ds4_role, the backend behaves as a normal single-node ds4 model. |
ds4_layers:0:19 | The coordinator’s own layer slice (inclusive). |
ds4_listen:0.0.0.0:1234 | Address that workers dial into. |
ds4_route_timeout:60 | Optional. Seconds the coordinator waits for the worker route to form before returning an error on a request. Defaults to 60. |
Warning
Worker↔coordinator traffic is plaintext and unauthenticated: there is no TLS or auth on this channel. Bind ds4_listen to an address on a trusted/private network only; using 0.0.0.0 exposes the coordinator on every interface. Run the layer split exclusively over a network you control.
Once the model is loaded, the coordinator serves requests exactly like a single-node ds4 model: generation goes through the ordinary inference path and is transparently routed across the layer slices.
Worker setup
On each worker machine (with the GGUF present locally), start a worker pointed at the coordinator:
local-ai worker ds4-distributed resolves the ds4 backend and execs the packaged ds4-worker binary, passing everything after -- straight through.
Layer-range semantics
- Ranges are inclusive:
0:19is layers 0 through 19. N:outputmeans layer N through the final layer plus the output head. The last worker normally owns the output head.- The coordinator and all connected workers together must cover every layer. Until they do, the coordinator returns a gRPC
UNAVAILABLEerror on inference requests (so a worker that starts slightly after the coordinator is tolerated: once it connects and the route is complete, requests succeed). The wait is tunable viads4_route_timeout.
Note
ds4 layer-split inference is manual setup in this release (Phase 1): you place the coordinator config and launch each worker yourself, and the layer ranges must be partitioned by hand so they cover the whole model. P2P auto-discovery of the coordinator is planned for a later phase.
Scaling
Adding worker capacity: Start additional worker instances pointing to the same frontend. They self-register automatically:
Multiple frontend replicas: Run multiple LocalAI frontends behind a load balancer. Since all state is in PostgreSQL and coordination is via NATS, frontends are fully stateless and interchangeable.
Model Scheduling
Model scheduling controls where models are placed and how many replicas are maintained. In the React WebUI it has its own Scheduling page (a top-level nav item, separate from the Nodes page). It combines two optional features:
Node Selectors
Pin models to nodes with specific labels. Only nodes matching all selector labels are eligible:
Without a node selector, models can schedule on any healthy node (default behavior).
Replica Auto-Scaling
Control the number of model replicas across the cluster:
| Field | Description |
|---|---|
min_replicas | Minimum replicas to maintain (0 = no minimum, single replica default) |
max_replicas | Maximum replicas allowed (0 = unlimited) |
Auto-scaling is only active when min_replicas > 0 or max_replicas > 0.
The Replica Reconciler runs as a background process on the frontend:
- Scale up: Adds replicas when all existing replicas are busy (have in-flight requests)
- Scale down: Removes idle replicas after 5 minutes of inactivity
- Maintain minimum: Ensures
min_replicasare always loaded (recovers from node failures) - Eviction protection: Models with auto-scaling enabled are never evicted below
min_replicas - Restart-safe: Per-model load metadata (backend type +
ModelOptions) is persisted in themodel_load_infosPostgreSQL table on the first successful dispatch, so a frontend restart or rolling upgrade does not require a fresh inference request to repopulate state before the reconciler can scale up replacement replicas.
All fields are optional and composable:
- Node selector only: pin model to matching nodes, single replica
- Replicas only: auto-scale across all nodes
- Both: auto-scale on matching nodes only
Declarative per-model scheduling (unattended installs)
In distributed mode you can declare per-model scheduling at startup, instead of using the WebUI/API. Config is authoritative: it is re-applied on every boot and overwrites the listed models (models not listed are left untouched).
| Variable | Description |
|---|---|
LOCALAI_MODEL_SCHEDULING | Inline JSON list of scheduling entries |
LOCALAI_MODEL_SCHEDULING_CONFIG | Path to a YAML file with the same list |
Entry fields: model_name (required), node_selector (a label map; omit it to
match every node), and then one of two replica modes (they are mutually
exclusive):
replicas: all- static spread: place exactly one replica on every matching node, proactively, regardless of load, and keep it in sync as nodes join and leave. Use this for “run model X everywhere (with this label)”.min_replicas/max_replicas- elastic auto-scaling: keep at leastmin_replicasrunning, and burst up tomax_replicasonly when all replicas are busy, scaling back down to the minimum when idle.max_replicas: 0means no upper bound (grow to cluster capacity). To enable this mode you must setmin_replicas >= 1ormax_replicas >= 1- an entry with onlymax_replicas: 0(and noreplicas: all) does nothing.
Net effect at a glance:
| Config | Behavior |
|---|---|
replicas: all | One replica per matching node, placed immediately, tracks join/leave |
min_replicas: 1, max_replicas: 0 | Always >=1, bursts to cluster capacity under load, back to 1 when idle |
min_replicas: 2, max_replicas: 4 | Always >=2, bursts to at most 4 under load |
node_selector constrains which nodes a model may use; with no selector the
model may use all healthy nodes. So “spread model X across all nodes” is just
replicas: all with no node_selector. replicas: all targets one replica per
matching node; with the default per-node cap of one replica per model this lands
exactly one on each node (see the note below about LOCALAI_MAX_REPLICAS_PER_MODEL).
YAML example (scheduling.yaml):
Inline equivalent:
Notes:
- Because the config is authoritative, each listed model’s entire scheduling
row is replaced on every boot, including the optional prefix-cache routing
overrides (
route_policy,balance_abs_threshold,balance_rel_threshold,min_prefix_match). For a model you manage via this config, set those fields here too if you need non-default values; values set only through the API are reset on the next restart. Models not listed in the config are never touched. replicas: allplaces one replica per matching node by relying on the default per-node cap of one replica per model. If you raiseLOCALAI_MAX_REPLICAS_PER_MODELon a worker above 1, the target count can be met by stacking replicas on fewer nodes rather than spreading one to each.
Label Management API
| Method | Path | Description |
|---|---|---|
GET | /api/nodes/:id/labels | Get labels for a node |
PUT | /api/nodes/:id/labels | Replace all labels (JSON object) |
PATCH | /api/nodes/:id/labels | Merge labels (add/update) |
DELETE | /api/nodes/:id/labels/:key | Remove a single label |
Scheduling API
| Method | Path | Description |
|---|---|---|
GET | /api/nodes/scheduling | List all scheduling configs |
GET | /api/nodes/scheduling/:model | Get config for a model |
POST | /api/nodes/scheduling | Create/update config |
DELETE | /api/nodes/scheduling/:model | Remove config |
Comparison with P2P
| P2P / Federation | Distributed Mode | |
|---|---|---|
| Discovery | Automatic via libp2p token | Self-registration to frontend URL |
| State storage | In-memory / ledger | PostgreSQL |
| Coordination | Gossip protocol | NATS messaging |
| Node management | Automatic | REST API + WebUI |
| Health monitoring | Peer heartbeats | Centralized HealthMonitor |
| Backend management | Manual per node | Dynamic via NATS backend.install |
| Best for | Ad-hoc clusters, community sharing | Production, Kubernetes, managed infrastructure |
| Setup complexity | Minimal (share a token) | Requires PostgreSQL + NATS |
Troubleshooting
Worker not registering:
- Verify the frontend URL is reachable from the worker (
curl http://frontend:8080/api/node/register) - Check that
--registration-tokenmatches on both frontend and worker - Ensure auth is enabled on the frontend (
LOCALAI_AUTH=true)
NATS connection errors:
- Confirm NATS is running and reachable (
nats-server --signal ldmor check port 4222) - Check that
--nats-urluses the correct hostname/IP from the worker’s network perspective
PostgreSQL connection errors:
- Verify the connection URL format:
postgresql://user:password@host:5432/dbname?sslmode=disable - Ensure the database exists and the user has CREATE TABLE permissions (for auto-migration)
- Check that pgvector extension is installed if using RAG features
Node shows as unhealthy or offline:
- The HealthMonitor marks nodes offline when heartbeats are missed. Check network connectivity between worker and frontend.
- Verify
--heartbeat-intervalis not set too high - Offline nodes automatically restore to healthy when they re-register (no re-approval needed)
Backend not installing:
- Check the worker logs for
backend.installevents
Port conflicts on workers:
- Each model gets its own gRPC process on an incrementing port (50051, 50052, …)
- The HTTP file transfer server runs on the base port - 1 (default: 50050)
- Ensure the port range is not blocked by firewalls or used by other services
- Verify the backend gallery configuration is correct
- The worker needs network access to download backends from the gallery
Roadmap: Routing and Caching Enhancements
The scheduling algorithm above is load-based (least in-flight, then least-recently-used). Work is underway to make routing prefix-cache-aware: bias each request toward the replica that already holds the relevant KV/prefix cache (multi-turn conversations and shared system prompts), so backends reuse cache instead of recomputing it. The first step is a router-side radix tree of prompt-prefix hashes mapped to nodes, with longest-prefix match, a load guard that preserves round-robin behavior under imbalance, and NATS sync across frontends. It is purely a routing-layer hint (no backend changes) and never routes worse than today’s round-robin.
Further enhancements, surfaced from a survey of SGLang, vLLM production-stack, Ray Serve, llm-d, AIBrix, and NVIDIA Dynamo, are tracked under the routing roadmap epic (#10063):
- Reported/precise KV-event mode (#10064): subscribe to actual backend KV-cache events for exact residency instead of inferring it from routing history.
- Multi-tier cache-overlap scoring (#10065): credit GPU/CPU/disk cache tiers separately.
- Pluggable scorer/filter/picker pipeline (#10066): composable multi-signal routing (cache, queue depth, KV utilization, latency).
- Load-shaping (#10067): anti-herding (softmax/temperature) and dispatch-time freshness.
- Prefill/decode disaggregation routing (#10068): route prefill and decode to separate pools with KV transfer.
- Per-user fairness (VTC) (#10069): balance per-user token usage against pod load.
- Minor tuning + MCP parity (#10070): per-model TTL override, probabilistic LRU updates, and MCP scheduling-config tool parity.