Fine-Tuning
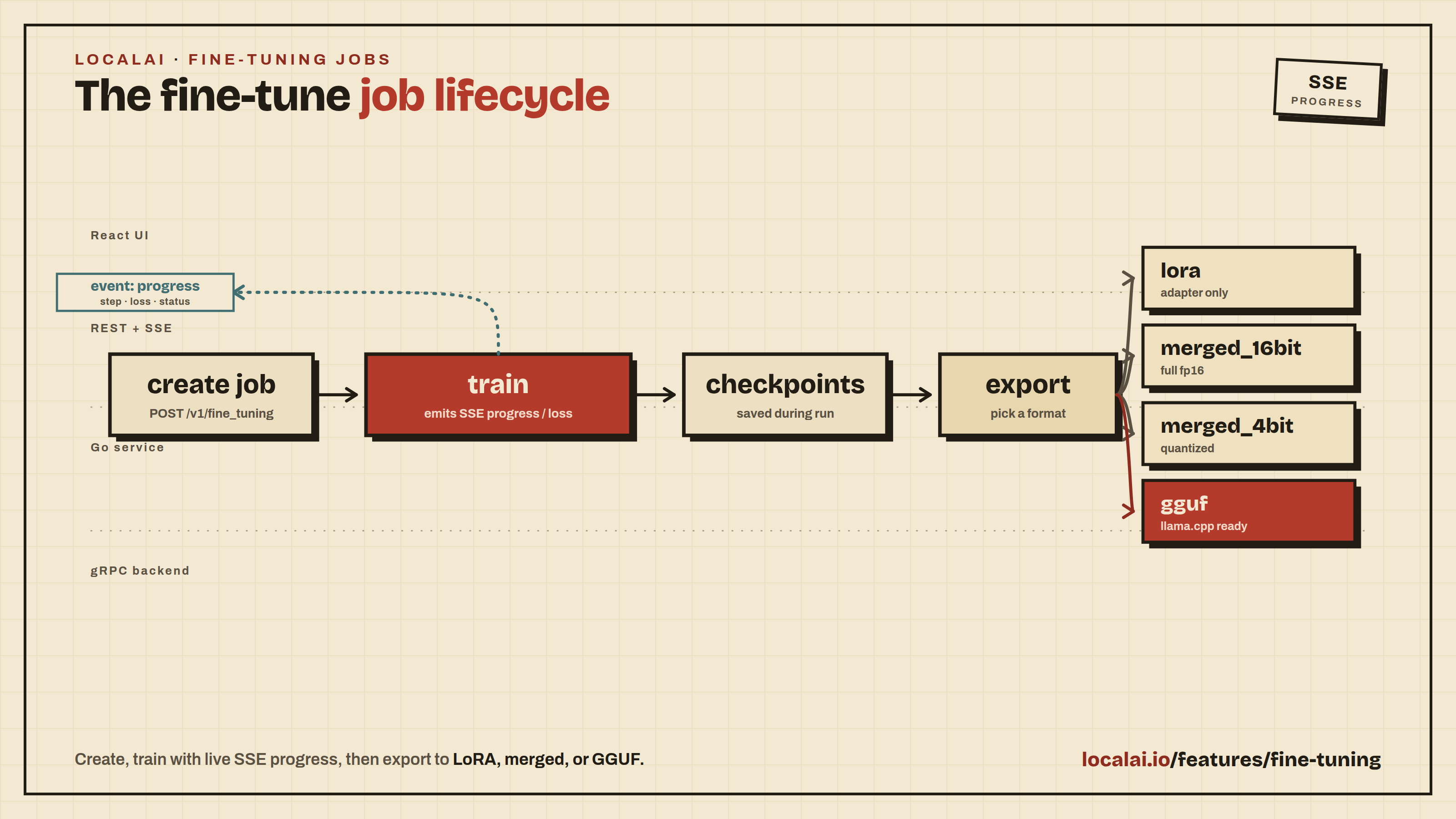
LocalAI supports fine-tuning LLMs directly through the API and Web UI. Fine-tuning is powered by pluggable backends that implement a generic gRPC interface, allowing support for different training frameworks and model types.
Supported Backends
| Backend | Domain | GPU Required | Training Methods | Adapter Types |
|---|---|---|---|---|
| trl | LLM fine-tuning | No (CPU or GPU) | SFT, DPO, GRPO, RLOO, Reward, KTO, ORPO | LoRA, Full |
Availability
Fine-tuning is always enabled. When authentication is enabled, fine-tuning is a per-user feature (default OFF). Admins can enable it for specific users via the user management API.
Note
This feature is experimental and may change in future releases.
Quick Start
1. Start a fine-tuning job
2. Monitor progress (SSE stream)
3. List checkpoints
4. Export model
API Reference
Endpoints
| Method | Path | Description |
|---|---|---|
POST | /api/fine-tuning/jobs | Start a fine-tuning job |
GET | /api/fine-tuning/jobs | List all jobs |
GET | /api/fine-tuning/jobs/:id | Get job details |
DELETE | /api/fine-tuning/jobs/:id | Stop a running job |
GET | /api/fine-tuning/jobs/:id/progress | SSE progress stream |
GET | /api/fine-tuning/jobs/:id/checkpoints | List checkpoints |
POST | /api/fine-tuning/jobs/:id/export | Export model |
POST | /api/fine-tuning/datasets | Upload dataset file |
Job Request Fields
| Field | Type | Description |
|---|---|---|
model | string | HuggingFace model ID or local path (required) |
backend | string | Backend name (default: trl) |
training_method | string | sft, dpo, grpo, rloo, reward, kto, orpo |
training_type | string | lora or full |
dataset_source | string | HuggingFace dataset ID or local file path (required) |
adapter_rank | int | LoRA rank (default: 16) |
adapter_alpha | int | LoRA alpha (default: 16) |
num_epochs | int | Number of training epochs (default: 3) |
batch_size | int | Per-device batch size (default: 2) |
learning_rate | float | Learning rate (default: 2e-4) |
gradient_accumulation_steps | int | Gradient accumulation (default: 4) |
warmup_steps | int | Warmup steps (default: 5) |
optimizer | string | adamw_torch, adamw_8bit, sgd, adafactor, prodigy |
extra_options | map | Backend-specific options (see below) |
Backend-Specific Options (extra_options)
TRL
| Key | Description | Default |
|---|---|---|
max_seq_length | Maximum sequence length | 512 |
packing | Enable sequence packing | false |
trust_remote_code | Trust remote code in model | false |
load_in_4bit | Enable 4-bit quantization (GPU only) | false |
DPO-specific (training_method=dpo)
| Key | Description | Default |
|---|---|---|
beta | KL penalty coefficient | 0.1 |
loss_type | Loss type: sigmoid, hinge, ipo | sigmoid |
max_length | Maximum sequence length | 512 |
GRPO-specific (training_method=grpo)
| Key | Description | Default |
|---|---|---|
num_generations | Number of generations per prompt | 4 |
max_completion_length | Max completion token length | 256 |
GRPO Reward Functions
GRPO training requires reward functions to evaluate model completions. Specify them via the reward_functions field (a typed array) or via extra_options["reward_funcs"] (a JSON string).
Built-in Reward Functions
| Name | Description | Parameters |
|---|---|---|
format_reward | Checks <think>...</think> then answer format (1.0/0.0) | - |
reasoning_accuracy_reward | Extracts <answer> content, compares to dataset’s answer column | - |
length_reward | Score based on proximity to target length [0, 1] | target_length (default: 200) |
xml_tag_reward | Scores properly opened/closed <think> and <answer> tags | - |
no_repetition_reward | Penalizes n-gram repetition [0, 1] | - |
code_execution_reward | Checks Python code block syntax validity (1.0/0.0) | - |
Inline Custom Reward Functions
You can provide custom reward function code as a Python function body. The function receives completions (list of strings) and **kwargs, and must return list[float].
Warning
Inline reward code executes arbitrary Python and is disabled by default.
Inline code is compiled and run in the backend process. The restricted-builtins allowlist is not a security sandbox — trivial expressions can escape it to reach the host (arbitrary code execution). Because the fine-tuning endpoint is unauthenticated by default, inline reward functions are refused unless the operator explicitly opts in by setting LOCALAI_TRL_ALLOW_INLINE_REWARD=true on the backend.
Only enable it on a trusted, access-controlled instance where every caller of the fine-tuning API is authorized to run code on the host. Otherwise use the builtin reward functions above.
The function is given the reduced builtin set (len, int, float, str, list, dict, range, enumerate, zip, map, filter, sorted, min, max, sum, abs, round, any, all, isinstance, print) plus the re, math, json, and string modules, and is compiled and validated at job start (fail-fast on syntax errors). Treat these as ergonomics, not as an isolation boundary.
Example API Request
Export Formats
| Format | Description | Notes |
|---|---|---|
lora | LoRA adapter files | Smallest, requires base model |
merged_16bit | Full model in 16-bit | Large but standalone |
merged_4bit | Full model in 4-bit | Smaller, standalone |
gguf | GGUF format | For llama.cpp, requires quantization_method |
GGUF Quantization Methods
q4_k_m, q5_k_m, q8_0, f16, q4_0, q5_0
Web UI
When fine-tuning is enabled, a “Fine-Tune” page appears in the sidebar under the Agents section. The UI provides:
- Job Configuration - Select backend, model, training method, adapter type, and hyperparameters
- Dataset Upload - Upload local datasets or reference HuggingFace datasets
- Training Monitor - Real-time loss chart, progress bar, metrics display
- Export - Export trained models in various formats
Dataset Formats
Datasets should follow standard HuggingFace formats:
- SFT: Alpaca format (
instruction,input,outputfields) or ChatML/ShareGPT - DPO: Preference pairs (
prompt,chosen,rejectedfields) - GRPO: Prompts with reward signals
Supported file formats: .json, .jsonl, .csv
Architecture
Fine-tuning uses the same gRPC backend architecture as inference:
- Proto layer:
FineTuneRequest,FineTuneProgress(streaming),StopFineTune,ListCheckpoints,ExportModel - Python backends: Each backend implements the gRPC interface with its specific training framework
- Go service: Manages job lifecycle, routes API requests to backends
- REST API: HTTP endpoints with SSE progress streaming
- React UI: Configuration form, real-time training monitor, export panel