Middleware: PII filtering and intelligent routing
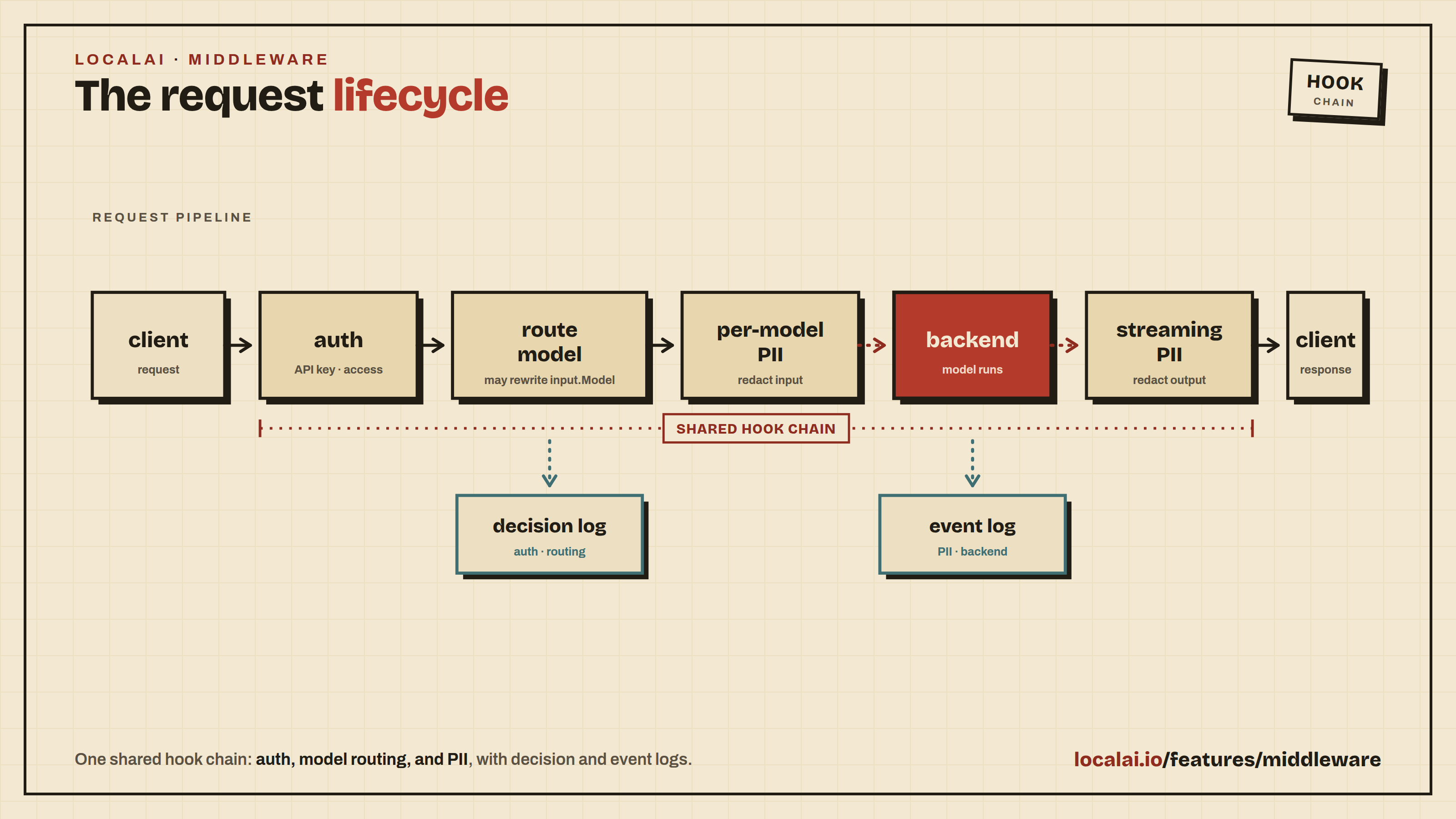
LocalAI ships a request-middleware layer that sits between the HTTP API and
the backend dispatcher. Two subsystems share that layer because they share
the same lifecycle hook: PII filtering scans the request body before it
reaches a backend, and the intelligent router rewrites input.Model so
a single client-facing model name fans out across multiple downstream
targets.
Both are inspected and configured from the same admin page
(/app/middleware), backed by the same REST surface (/api/middleware/*,
/api/pii/*, /api/router/*) and the same MCP tools.
Request lifecycle
The router runs first (it picks the target model so per-model PII has
something to gate on), per-model PII runs next (gated by the resolved
config), and the backend executes. Filtering is request-side only -
the request body is scanned and rewritten before forwarding; the response
is not touched (NER over a streamed response is left as a follow-up). Each
subsystem writes to its own admin-visible log: /api/router/decisions for
routing, /api/pii/events for redaction and block actions.
PII filtering
PII redaction is NER-based and runs request-side (input). It is
off by default, flipping to on for any cloud-proxy backend
because that traffic crosses the network to a third-party provider. Pick a
default detector so those models are actually
scanned. Explicit pii.enabled in a model’s YAML always wins over the
backend default.
Filtering runs on every text-accepting endpoint that has an adapter wired:
/v1/chat/completions and /v1/messages (chat), /v1/completions,
/v1/embeddings, /v1/edits, and the Ollama /api/chat, /api/generate
and /api/embed endpoints, plus the MITM proxy
request body. Image, audio (TTS/STT), video, rerank, and the realtime
WebSocket are not filtered yet (different prompt-PII semantics; realtime is
not HTTP middleware).
A request’s messages are scanned as one document (joined in order), so
the NER detector keeps conversational context: whether 4421 is a PIN or
jdoe_42 is a username is usually decided by the question asked in the
previous message, and a bidirectional encoder only sees that context when
the messages share a forward pass. Detected spans are mapped back to the
individual message they fall in, so redaction still rewrites each message
field in place and events carry message-local offsets.
The earlier regex pattern tier (
pii.patterns, the built-in pattern catalogue,--pii-config, the/api/pii/patterns|test|decideendpoints) and response/streaming-side redaction have been removed. Detection is now driven entirely by token-classification (NER) models. Legacy keys no-op with a startup warning.
Detector models
A detector is a token_classify model (e.g. an openai-privacy-filter
GGUF) that carries the detection policy in a top-level pii_detection:
block - defined once, on the model itself:
mask rewrites the matched span to [REDACTED:ner:<GROUP>] in the request
body before forwarding. block returns HTTP 400 (error.type=pii_blocked)
without forwarding. allow detects and logs (a PIIEvent is still recorded)
but leaves the text unchanged. The entity-group names are whatever the model
emits (the privacy-filter family uses uppercase names like EMAIL,
PASSWORD, CREDITCARD).
Pattern detector tier
NER is the wrong tool for high-entropy, highly-regular secrets - API keys, tokens, private-key blocks. A trained NER model has no “API key” class, so it fragments a key into the nearest categories it does know and can leave the secret part exposed. Those secrets are exactly what a regex catches cheaply.
A pattern detector is a detector model (backend: pattern) that matches
secrets with a restricted regex subset compiled to Go’s RE2 engine -
linear-time, no backtracking, no ReDoS. It runs entirely in-process: no model
download, no backend, zero VRAM. Install the gallery’s secret-filter for a
ready-made set, or define your own:
A match is reported under its group (built-in group name, or the pattern
name), so entity_actions / default_action apply exactly as for NER.
The restricted grammar (validated at load - an invalid pattern is rejected, not silently ignored):
- Allowed: literals, character classes
[…]and\w \d \s, alternation, anchors^ $ \b, and quantifiers? * + {m,n}. - Rejected:
.(any-char), capturing groups, and{n,m}bounds over 4096. - Required anchor: every pattern must contain a fixed literal run of at
least 3 characters (e.g.
sk-ant-,ghp_,AKIA). This admits real key shapes but rejects open-ended ones - an email or a bare\w+has no such anchor and belongs to the NER tier.
Use both tiers together: reference an NER detector and a pattern detector in a
model’s pii.detectors (or as instance defaults); their hits union, and a
block from either rejects the request.
Consuming models
Any model opts in by enabling PII and referencing one or more detectors - no per-consumer policy:
Multiple detectors union their detections; overlapping spans resolve to
the strongest action (block > mask > allow). A configured detector
that can’t be loaded fails the request closed (HTTP 503,
error.type=pii_ner_unavailable) rather than silently skipping the check.
The same NER path runs on the MITM proxy
request body for intercepted hosts. Response/output redaction is out of
scope for now.
Instance-wide default detector
The Detector models table on the Middleware → Filtering page lists every
token_classify detector model (neural NER models and in-process pattern
matchers alike) and exposes a per-row Default toggle. Toggling a detector
on adds it to the instance-wide default detector set - one or more models
applied to any PII-enabled model that names none of its own pii.detectors.
It is persisted through POST /api/settings and read live, so a change takes
effect on the next request without a restart. A default that names a model no
longer loaded still appears (marked not loaded) so it can be toggled off.
The default set can also be supplied out-of-band with the
LOCALAI_PII_DEFAULT_DETECTORS environment variable (comma-separated model
names, e.g. privacy-filter-nemotron,secret-filter). When set it takes
precedence over the value persisted via the UI (env > file), which is the
right behaviour for immutable container deployments that pin filtering policy
at boot rather than via the admin UI.
This is what makes cloud-proxy / MITM redaction work out of the box: those
backends default to PII-enabled but ship no detector list, so without a
default detector the filter runs with nothing to scan. Set one here and
cloud-proxy traffic is scanned with no per-model config.
Resolution precedence (the single decision point is ResolvePIIPolicy,
shared by the chat middleware and the MITM listener so both agree):
- An explicit
pii.enabledon the model wins -trueorfalse. - Otherwise PII is on if the backend defaults it on (
cloud-proxy). - Detectors are the model’s own
pii.detectors; if it lists none, the instance-wide default detector(s) are used.
A model that resolves enabled but ends up with no detector at all (a cloud-proxy model with no model detectors and no instance default) scans nothing - set a default detector to close that gap.
Admin page
The /app/middleware page (admin role only) has four tabs - Filtering,
Routing, MITM Proxy (see the MITM doc),
and Events. The Filtering tab has a Detector models table (every
token_classify filter model, with the per-row Default toggle above and an
edit link to each detector’s config, plus an Add detector model button) and
a per-model table listing only the models PII can actually apply to - chat /
completion / embeddings / edit consumers and cloud-proxy models, not
VAD/STT/image models or the detector models themselves. Each row reports the
effective enabled state as an inline toggle - flipping it writes an
explicit pii.enabled to that model’s YAML (a server-side deep-merge that
preserves pii.detectors and every other field), so a cloud-proxy model shown
on by backend default can be turned off, and vice-versa - plus the
resolved detector(s) - with a (default) marker when they come from the
instance-wide default rather than the model’s YAML - why it is on (YAML /
backend default), and the recent event count. Detection policy
(entity→action, min score) is still edited on each detector model’s config
(Models → edit → PII), not globally.
Analyze / redact API
The same detection pipeline is also exposed as a standalone service, so a
client can scan or sanitise a string without routing a full chat request
through it (the inline path above). Two endpoints, both requiring a normal API
key (the pii_filter feature - not admin):
POST /api/pii/analyze- detect only. Returns the matched entity spans (entity_type,sourcener|pattern,start/end,score,action) and ablockedflag, without modifying the text.POST /api/pii/redact- apply the configured policy. Returnsredacted_text(with masked spans replaced by[REDACTED:<id>]) andmasked; when ablockaction fires it returns400withtype: pii_blockedand the offending entities - never a redacted body.
Both take the same request: text plus a detector selection - either explicit
detector model names in detectors, or a consuming model whose effective
policy is used: the model’s own pii.detectors, else the
instance-wide default detectors, exactly as
the inline filter resolves them. A model with PII disabled - or enabled but
with no detector anywhere - is a 400: the inline filter would scan nothing
for it, and the API says so rather than implying a clean scan. The detection
policy lives on the detector models exactly as for the inline filter. The raw
matched value is never returned (an admin may pass reveal: true to include
the audit hash_prefix).
text is scanned as a single document. To reproduce the inline filter’s
conversation-context behaviour for multi-message content, join the messages
with blank lines into one text - NER detection quality depends on that
context (a bare 4421 is nothing; after “what are the last four digits of
your card?” it is a PIN).
Calls are audited in the same event log, tagged with an origin of
pii_analyze / pii_redact (the inline filter records middleware, the MITM
proxy records proxy), so GET /api/pii/events?origin=pii_redact shows just
the redact-API rows.
REST surface
| Method | Path | Auth | Purpose |
|---|---|---|---|
| POST | /api/pii/analyze | api key (pii_filter) | Detect PII in a string; returns entity spans, no mutation. |
| POST | /api/pii/redact | api key (pii_filter) | Redact a string per policy; returns redacted_text or 400 pii_blocked. |
| GET | /api/pii/events | admin | Recent middleware events - PII redactions, MITM connect/traffic, admission denials. Filterable by correlation_id, user_id, pattern_id (e.g. ner:EMAIL), kind, origin. |
| GET | /api/middleware/status | admin | Aggregated dashboard data: per-model PII state + detectors + router status + MITM status + admission status. One round-trip for the UI. |
MCP tools
The same surface is mirrored through the LocalAI Assistant MCP server:
| Tool | Read/Write | Purpose |
|---|---|---|
get_pii_events | read | Recent redaction / block events with optional filters. |
get_middleware_status | read | Aggregator - the same payload as GET /api/middleware/status. |
Detection policy is part of a detector model’s config, so it is managed
through the model-config tools (edit_model_config), not a dedicated PII
tool.
Intelligent routing
A router model is a model whose YAML carries a router: block. When
a client addresses it ("model": "smart-router"), the middleware
classifies the prompt, picks a downstream candidate model, rewrites
input.Model to the candidate, and the standard model-resolution path
runs against that resolved target. ACL checks, disabled-state, and
per-model PII all apply to the resolved model - the router does
model selection only.
Depth-1 invariant
Candidates must not themselves be router models. A
smart-router → claude-strict → cloud-proxy chain is fine
(claude-strict is a regular cloud-proxy model). A
smart-router → other-router → real-model chain is rejected at runtime
by the middleware (the dispatcher returns HTTP 500 with a
depth-1 invariant error). This keeps the dispatch graph acyclic and
predictable.
Fallback
If no candidate’s label set covers the active label set from the classifier,
or the classifier errors out, the router uses cfg.Router.Fallback.
An empty fallback causes the dispatch to fail with HTTP 500 rather
than silently routing somewhere unintended - fail-fast, not
silent-bypass.
Available classifiers
LocalAI ships two classifier implementations. Pick one with classifier:
in the router YAML:
| Classifier | When to use | Underlying primitive |
|---|---|---|
score (default) | Small classifier-tuned LM (Arch-Router-style). Best when label vocabulary is well-covered by next-token continuation. | Score gRPC primitive (llama-cpp, vLLM). |
colbert | When label descriptions are abstract or short and a next-token classifier produces flat distributions. Robust on long-form policy descriptions. | rerankers backend in ColBERT mode (e.g. bge-m3-colbert from the gallery). |
Both classifiers share the same YAML shape: classifier_model,
policies, candidates, fallback, activation_threshold,
classifier_cache_size, and the optional embedding_cache block.
The Score classifier
The score classifier works like this:
- Build a Qwen/ChatML system prompt that lists every policy label with its description and primes the model to emit a label as the assistant turn.
- Ask the classifier model to score every policy label as the
first-token(s) continuation. This uses the
ScoregRPC primitive (backend.proto::Score), which returns per-candidate log-probabilities length-normalized so candidates of unequal token length stay comparable. - Softmax the length-normalized log-probabilities into a probability distribution over labels.
- Threshold the distribution: every label whose probability passes
activation_thresholdjoins the active label set. - Pick the FIRST candidate whose
Labelsis a superset of the active set. Admins order candidates smallest → largest so a single-label query routes to the smallest capable model, while a query that activates multiple labels falls to a candidate that covers them all.
This is the Arch-Router approach extended for multi-label. The distribution carries more signal than the argmax - reading off the spread lets one prompt activate multiple policies and route to a model capable of all of them.
Recommended classifier model
Arch-Router-1.5B is the canonical choice. It’s a Qwen-2.5-1.5B-Instruct base trained specifically on routing-policy continuation, so the ChatML system-prompt
- label-continuation pattern produces well-separated label probabilities without prompt tuning. The Q4_K_M GGUF runs on CPU, GPU, and Intel SYCL.
The classifier model must support the Score gRPC primitive (today: the
llama-cpp and vLLM backends) and use the ChatML chat template. Any small
ChatML instruct model works under those constraints, but expect flatter
probability distributions which translate to a higher
activation_threshold to keep noise out of the active label set.
On llama-cpp, scoring rides the server’s task queue alongside
generation and embeddings, so the classifier may share a model config
with chat/completion/embeddings - a dedicated scorer model is no
longer required. Repeated calls with the same prompt also reuse the
prompt’s KV cache across candidates.
The Colbert classifier
The colbert classifier reranks each policy description against the
prompt via the rerankers backend and activates the labels whose
relevance scores clear activation_threshold (default 0.5 for
reranker-style scores in [0, 1]).
The reranker scores the description (natural English) rather than
asking a small LM to score the label as a next-token continuation,
so it tends to be more robust when policy labels are abstract slugs
(compliance-review, tier-2-support). The trade-off is one
reranker round-trip per request - bge-m3 in ColBERT mode is fast
enough on GPU that this is comparable to the Score path for most
workloads. The embedding_cache block applies identically.
The reranker model’s type: (in the model YAML) selects which
underlying scoring head loads - colbert for late-interaction MaxSim,
cross-encoder for cross-attention scoring. The classifier itself is
indifferent; pick the head that fits your latency / quality budget.
YAML reference
Tuning activation_threshold
The threshold is the single knob you’ll want to tune per (classifier-model, policy-set) pair. On Arch-Router-1.5B with the three-policy setup above, sweeping the threshold over a hand-labeled 30-prompt corpus produced:
| Threshold | Label-set accuracy | End-to-end routing accuracy |
|---|---|---|
| 0.15 (package default) | 30% | 73% |
| 0.30 | 57% | 87% |
| 0.40 | 60% | 90% |
| 0.45 | 67% | 97% |
| 0.50 | 67% | 97% |
The classifier’s argmax matches the dominant label 93% of the time on this corpus - what the threshold controls is how much secondary-label noise leaks into the active label set. Low thresholds push single-label queries to multi-label-capable (larger) candidates unnecessarily; 0.40 keeps the dominant label dominant without losing genuine compound activations.
Re-tune per (classifier-model, policy-set) pair. The /api/score
endpoint (see below) is the convenient probe - it returns the raw
length-normalized log-probabilities so you can sweep thresholds offline
without driving real chat completions.
Embedding cache (L2)
Classification is the most expensive thing the middleware does. The score classifier already memo-caches verbatim repeats (case- and whitespace-folded prompt → decision); the embedding cache is the L2 tier that catches semantically similar prompts - “How do I exit vim?” and “i need to quit vim” can share a decision instead of running the classifier twice.
Pairs naturally with a larger / slower classifier model: the steady-state
cost on cache hits collapses to one embedding round-trip plus a KNN
search, both well under 100ms with nomic-embed-text-v1.5 + local-store.
Configuration
Add an embedding_cache: block to a router model:
Omit the block entirely to disable. The cache adds two new failure modes (embedder unavailable, store unavailable) - both fall through to the inner classifier so routing keeps working.
How it works
For each request:
- Embed the probe prompt via the configured
embedding_model. - KNN top-1 against the per-router local-store collection.
- If similarity ≥
similarity_threshold, return the cached decision (Cached=true,CacheSimilarity=<sim>in the decision log). - Miss → run the inner classifier. If
decision.score >= confidence_threshold, insert(embedding, decision)into the store. Low-confidence decisions are deliberately skipped so they can’t poison future paraphrases.
The local-store collection is named router-cache-<router-model-name> by
default - each router gets its own collection so two routers can’t
cross-contaminate. Collections persist on disk (local-store is the
canonical persistent vector backend), so the cache survives restarts.
Tuning notes
- Similarity threshold: 0.80 is the package default - re-tune per (embedding model, corpus). The histogram on the Routing tab shows where the cosine distribution actually sits; pick a threshold above the cross-intent cluster and below the paraphrase cluster.
- Confidence threshold: 0.60 corresponds roughly to “the classifier is committed to a top label.” Don’t lower this - caching unsure decisions propagates the uncertainty.
- Cache flush: invalidates automatically when the router YAML
changes (the classifier cache is fingerprinted by
yaml.Marshal), but the underlying local-store collection still holds the old payloads. Manual flush via local-store admin or by renamingstore_nameif you need a hard reset. - Latency budget: an embedding round-trip (typically 30-80ms for small embedding models) plus KNN search (~5ms) is added to every miss on top of the classifier latency. Cache hits skip the classifier entirely. Break-even is around 7-10% hit rate; agent loops with repeated phrasing easily exceed this.
Admin page
The /app/middleware page has a Routing tab listing every router
model’s classifier, policies, candidates, and fallback. The Events
tab shows the decision log - one row per classified request with
correlation ID, requested model, served model, classifier name, active
labels, top-label score, and latency.
Routing decisions are stored in an in-process ring buffer (default
capacity 5,000). The decision log is for audit and tuning - the
canonical usage log lives in /api/usage and correlates by request ID.
REST surface
| Method | Path | Auth | Purpose |
|---|---|---|---|
| GET | /api/router/status | any | Router configuration: each router model’s classifier, policies, candidates. |
| GET | /api/router/decisions | admin | Decision log with optional filters (correlation_id, user_id, router_model, limit). |
| POST | /api/score | admin | Direct access to the Score gRPC primitive - useful for offline threshold tuning. Body: {"model": "<classifier-model>", "prompt": "<chatml-prompt>", "candidates": ["label-a", ...], "length_normalize": true}. The llama-cpp and vLLM backends implement Score; other backends return UNIMPLEMENTED. |
MCP tools
| Tool | Read/Write | Purpose |
|---|---|---|
get_router_decisions | read | Recent decision log with optional filters. |
get_middleware_status | read | Includes the router section listing configured router models. |
Mutating routing config - adding a candidate, changing the classifier
model - is YAML-only today; reload with POST /models/reload to pick
up edits without restarting.
Operational notes
- Reload after YAML edits. The router configs are loaded at startup
and cached.
POST /models/reloadre-reads from disk; the next request rebuilds the classifier from the new config (the classifier cache is fingerprinted byyaml.Marshal(RouterConfig)so it invalidates automatically). - Classifier latency on Arch-Router-1.5B Q4_K_M is ~500ms steady
for 3 policies on Intel SYCL. The score primitive re-decodes the full
prompt for every candidate today (the KV cache is cleared between
candidates); the prompt-KV-sharing optimization is on the perf TODO
list in
backend/cpp/llama-cpp/grpc-server.cpp::Score. Until then,classifier_cache_sizeis the highest-leverage knob for repeat-query workloads (agent loops). - Decision log size: 5,000-entry ring buffer per process. The log is in-process and not persisted - pair with the usage log for long-horizon audit.
Related features
- Cloud passthrough proxy - combine
the router with
proxy-*backends to send simple prompts to local models and complex ones to cloud providers. - MITM proxy - apply the same PII filter to Claude Code, Codex CLI, and any HTTPS client without LocalAI holding their API keys.
- Authentication - admin role is
required for mutating endpoints and the
/app/middlewarepage; in no-auth single-user mode the synthetic local user has admin role automatically.