OpenAI Functions and Tools
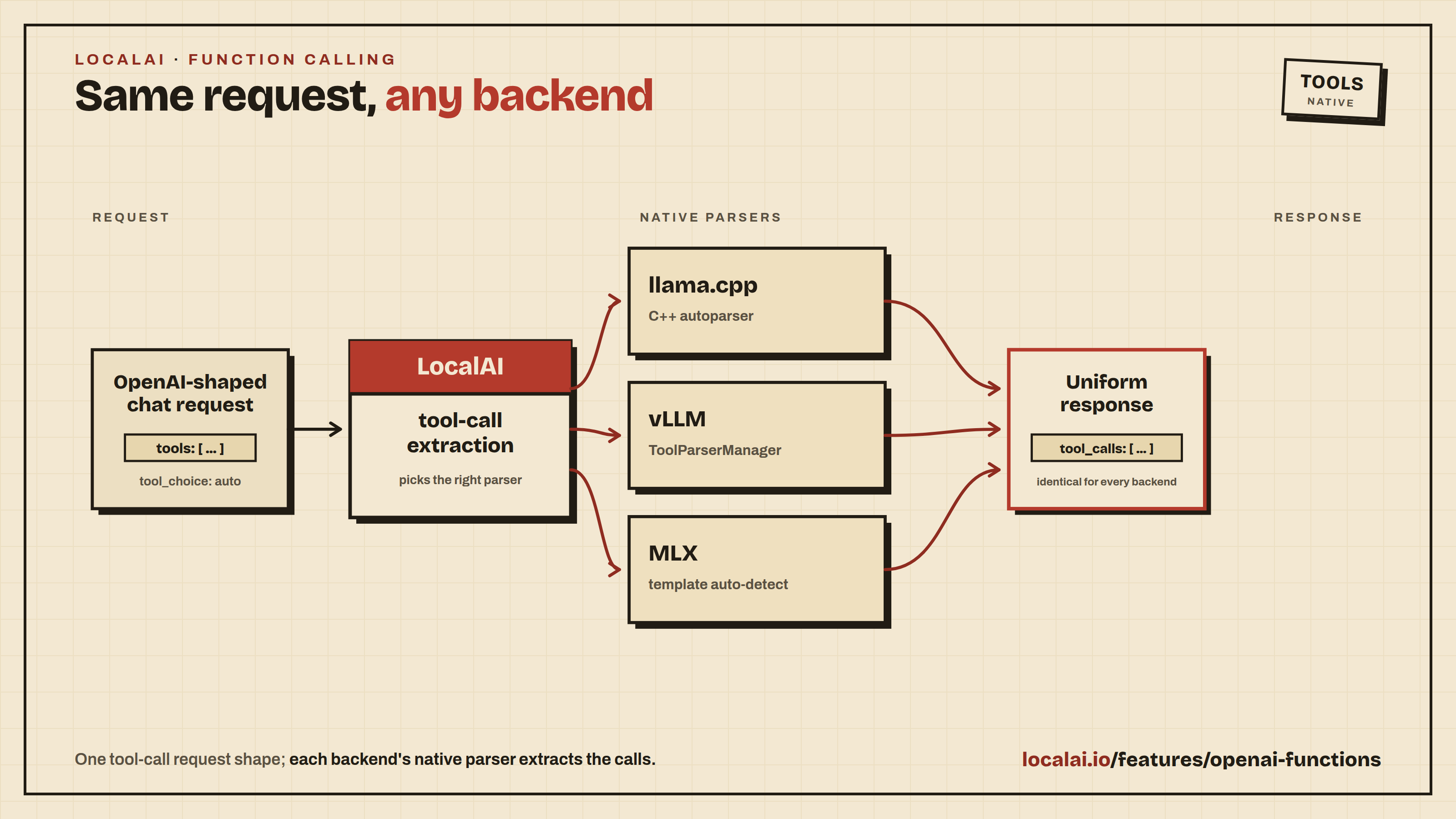
LocalAI supports running the OpenAI functions and tools API across multiple backends. The OpenAI request shape is the same regardless of which backend runs your model - LocalAI is responsible for extracting structured tool calls from the model’s output before returning the response.
To learn more about OpenAI functions, see also the OpenAI API blog post.
LocalAI also supports JSON mode out of the box on llama.cpp-compatible models.
💡 Check out LocalAGI for an example on how to use LocalAI functions.
Supported backends
| Backend | How tool calls are extracted |
|---|---|
llama.cpp | C++ incremental parser; any ggml/gguf model works out of the box, no configuration needed |
vllm | vLLM’s native ToolParserManager - select a parser with tool_parser:<name> in the model options. Auto-set by the gallery importer for known families |
vllm-omni | Same as vLLM |
mlx | mlx_lm.tool_parsers - auto-detected from the chat template, no configuration needed |
mlx-vlm | mlx_vlm.tool_parsers (with fallback to mlx-lm parsers) - auto-detected from the chat template, no configuration needed |
Reasoning content (<think>...</think> blocks from DeepSeek R1, Qwen3, Gemma 4, etc.) is returned in the OpenAI reasoning_content field on the same backends. When a model both reasons and calls a tool in the same turn, see Interleaved Thinking with Tool Calls for how the reasoning survives the tool-result round trip.
Setup
llama.cpp
No configuration required - the autoparser detects the tool call format for any ggml/gguf model that was trained with tool support.
vLLM / vLLM Omni
The parser must be specified explicitly because vLLM itself doesn’t auto-detect one. Pass it via the model options:
When you import a vLLM model through the LocalAI gallery, the importer looks up the model family and pre-fills tool_parser: and reasoning_parser: for you - you only need to override them for non-standard model names.
Available tool parsers include hermes, llama3_json, llama4_pythonic, mistral, qwen3_xml, deepseek_v3, granite4, kimi_k2, glm45, and more. Available reasoning parsers include deepseek_r1, qwen3, mistral, gemma4, granite. See the upstream vLLM documentation for the full list.
MLX / MLX-VLM
MLX backends auto-detect the right tool parser by inspecting the model’s chat template - you don’t need to set anything. Just load an MLX-quantized model that was trained with tool support:
The gallery importer will still append tool_parser: and reasoning_parser: entries to the YAML for visibility and consistency with the other backends, but those are informational - the runtime auto-detection in the MLX backend ignores them and uses the parser matched to the chat template.
Supported parser families: hermes/json_tools, mistral, gemma4, glm47, kimi_k2, longcat, minimax_m2, pythonic, qwen3_coder, function_gemma.
Usage example
You can configure a model manually with a YAML config file in the models directory, for example:
To use the functions with the OpenAI client in python:
For example, with curl:
Return data:
Advanced
Use functions without grammars
The functions calls maps automatically to grammars which are currently supported only by llama.cpp, however, it is possible to turn off the use of grammars, and extract tool arguments from the LLM responses, by specifying in the YAML file no_grammar and a regex to map the response from the LLM:
The response regex have to be a regex with named parameters to allow to scan the function name and the arguments. For instance, consider:
will catch
Parallel tools calls
This feature is experimental and has to be configured in the YAML of the model by enabling function.parallel_calls:
Use functions with grammar
It is possible to also specify the full function signature (for debugging, or to use with other clients).
The chat endpoint accepts the grammar_json_functions additional parameter which takes a JSON schema object.
For example, with curl:
Grammars and function tools can be used as well in conjunction with vision APIs:
💡 Examples
A full e2e example with docker-compose is available here.