Model Quantization
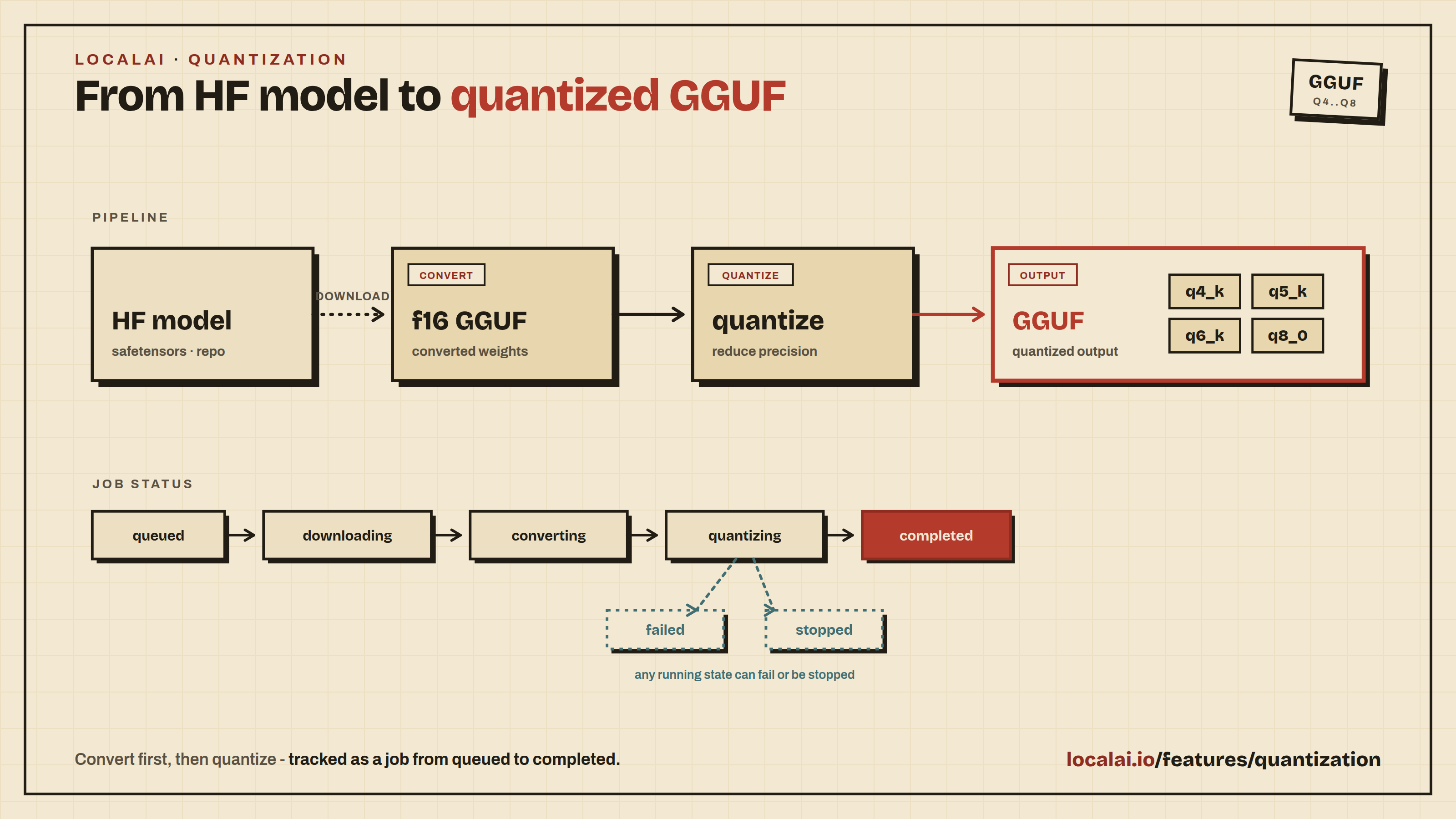
LocalAI supports model quantization directly through the API and Web UI. Quantization converts HuggingFace models to GGUF format and compresses them to smaller sizes for efficient inference with llama.cpp.
Note
This feature is experimental and may change in future releases.
Supported Backends
| Backend | Description | Quantization Types | Platforms |
|---|---|---|---|
| llama-cpp-quantization | Downloads HF models, converts to GGUF, and quantizes using llama.cpp | q2_k, q3_k_s, q3_k_m, q3_k_l, q4_0, q4_k_s, q4_k_m, q5_0, q5_k_s, q5_k_m, q6_k, q8_0, f16 | CPU (Linux, macOS) |
Quick Start
1. Start a quantization job
2. Monitor progress (SSE stream)
3. Download the quantized model
4. Or import it directly into LocalAI
API Reference
Endpoints
| Method | Path | Description |
|---|---|---|
POST | /api/quantization/jobs | Start a quantization job |
GET | /api/quantization/jobs | List all jobs |
GET | /api/quantization/jobs/:id | Get job details |
POST | /api/quantization/jobs/:id/stop | Stop a running job |
DELETE | /api/quantization/jobs/:id | Delete a job and its data |
GET | /api/quantization/jobs/:id/progress | SSE progress stream |
POST | /api/quantization/jobs/:id/import | Import quantized model into LocalAI |
GET | /api/quantization/jobs/:id/download | Download quantized GGUF file |
GET | /api/quantization/backends | List available quantization backends |
Job Request Fields
| Field | Type | Description |
|---|---|---|
model | string | HuggingFace model ID or local path (required) |
backend | string | Backend name (default: llama-cpp-quantization) |
quantization_type | string | Quantization format (default: q4_k_m) |
extra_options | map | Backend-specific options (see below) |
Extra Options
| Key | Description |
|---|---|
hf_token | HuggingFace token for gated models |
Import Request Fields
| Field | Type | Description |
|---|---|---|
name | string | Model name for LocalAI (auto-generated if empty) |
Job Status Values
| Status | Description |
|---|---|
queued | Job created, waiting to start |
downloading | Downloading model from HuggingFace |
converting | Converting model to f16 GGUF |
quantizing | Running quantization |
completed | Quantization finished successfully |
failed | Job failed (check message for details) |
stopped | Job stopped by user |
Progress Stream
The GET /api/quantization/jobs/:id/progress endpoint returns Server-Sent Events (SSE) with JSON payloads:
When the job completes, output_file contains the path to the quantized GGUF file and extra_metrics includes file_size_mb.
Quantization Types
| Type | Size | Quality | Description |
|---|---|---|---|
q2_k | Smallest | Lowest | 2-bit quantization |
q3_k_s | Very small | Low | 3-bit small |
q3_k_m | Very small | Low | 3-bit medium |
q3_k_l | Small | Low-medium | 3-bit large |
q4_0 | Small | Medium | 4-bit legacy |
q4_k_s | Small | Medium | 4-bit small |
q4_k_m | Small | Good | 4-bit medium (recommended) |
q5_0 | Medium | Good | 5-bit legacy |
q5_k_s | Medium | Good | 5-bit small |
q5_k_m | Medium | Very good | 5-bit medium |
q6_k | Large | Excellent | 6-bit |
q8_0 | Large | Near-lossless | 8-bit |
f16 | Largest | Lossless | 16-bit (no quantization, GGUF conversion only) |
The UI also supports entering a custom quantization type string for any format supported by llama-quantize.
Web UI
A “Quantize” page appears in the sidebar under the Tools section. The UI provides:
- Job Configuration - Select model, quantization type (dropdown with presets or custom input), backend, and HuggingFace token
- Progress Monitor - Real-time progress bar and log output via SSE
- Jobs List - View all quantization jobs with status, stop/delete actions
- Output - Download the quantized GGUF file or import it directly into LocalAI for immediate use
Architecture
Quantization uses the same gRPC backend architecture as fine-tuning:
- Proto layer:
QuantizationRequest,QuantizationProgress(streaming),StopQuantization - Python backend: Downloads model, runs
convert_hf_to_gguf.pyandllama-quantize - Go service: Manages job lifecycle, state persistence, async import
- REST API: HTTP endpoints with SSE progress streaming
- React UI: Configuration form, real-time progress monitor, download/import panel