Voice Recognition
LocalAI supports voice (speaker) recognition: speaker verification (1:1), speaker identification (1:N) against a built-in vector store, speaker embedding, and demographic analysis (age / gender / emotion from voice).
The audio analog to Face Recognition,
served over the same /v1/voice/* HTTP API by two backends:
voice-detect(recommended, default). A standalone C++/ggml engine (voice-detect.cpp): no Python, no onnxruntime, no torch runtime. Each gallery entry is a single self-describing GGUF. This is the recommended option for new deployments.speaker-recognition(Python). The original SpeechBrain / ONNX backend. Still supported; see the Python backend below.
Both backends expose the identical wire format, so the API examples on
this page work with either - only the gallery entry name (the model
field) changes.
voice-detect (ggml) backend
The voice-detect backend reads the embedding (or analysis)
architecture (voicedetect.arch) directly from the GGUF metadata, so
installing a gallery entry is all that is needed to select an engine. It
drives the VoiceEmbed / VoiceVerify / VoiceAnalyze gRPC rpcs behind the
/v1/voice/{embed,verify,analyze,register,identify,forget} endpoints.
Gallery entries
| Gallery entry | Model | Embedding dim | License |
|---|---|---|---|
voice-detect-ecapa-tdnn | SpeechBrain ECAPA-TDNN (VoxCeleb) | 192 | Apache 2.0 - commercial-safe |
voice-detect-wespeaker-resnet34 | WeSpeaker ResNet34 (VoxCeleb) | 256 | CC-BY-4.0 |
voice-detect-eres2net | 3D-Speaker ERes2Net (VoxCeleb) | 192 | Apache 2.0 - commercial-safe |
voice-detect-campplus | 3D-Speaker CAM++ (VoxCeleb) | 192 | Apache 2.0 - commercial-safe |
voice-detect-emotion-wav2vec2 | audEERING wav2vec2 (age / gender / emotion) | analyze head | CC-BY-NC-SA-4.0 - non-commercial |
The four speaker-recognition entries drive verify / embed / identify.
voice-detect-emotion-wav2vec2 is the analysis head behind
/v1/voice/analyze (continuous age estimate plus gender and emotion
class scores) and is non-commercial / research use only.
Quickstart
Install the default entry (recommended for copy-paste):
Verify that two audio clips were spoken by the same person:
Analyze age / gender / emotion (install the analyze entry first):
The 1:N register / identify / forget workflow and the rest of the API
are identical to the API reference below - just pass a
voice-detect-* model name. The default verify threshold is ~0.25 for
the ECAPA-TDNN / ERes2Net / CAM++ recognizers and ~0.30 for WeSpeaker
ResNet34.
speaker-recognition (Python) backend
The speaker-recognition backend follows the same two-engine pattern
under one image.
Engines
| Gallery entry | Model | Size | License |
|---|---|---|---|
speechbrain-ecapa-tdnn | ECAPA-TDNN on VoxCeleb (SpeechBrain) | ~17 MB | Apache 2.0 - commercial-safe |
wespeaker-resnet34 | WeSpeaker ResNet34 ONNX | ~26 MB | Apache 2.0 - commercial-safe |
Both entries are commercial-safe Apache-2.0. SpeechBrain is the
default - it’s a lightweight pure-PyTorch checkpoint that auto-
downloads on first use. The wespeaker-resnet34 entry wires the
direct-ONNX path for CPU-only deployments that don’t want the torch
runtime.
Quickstart
Install the default backend and model:
Verify that two audio clips were spoken by the same person:
Response:
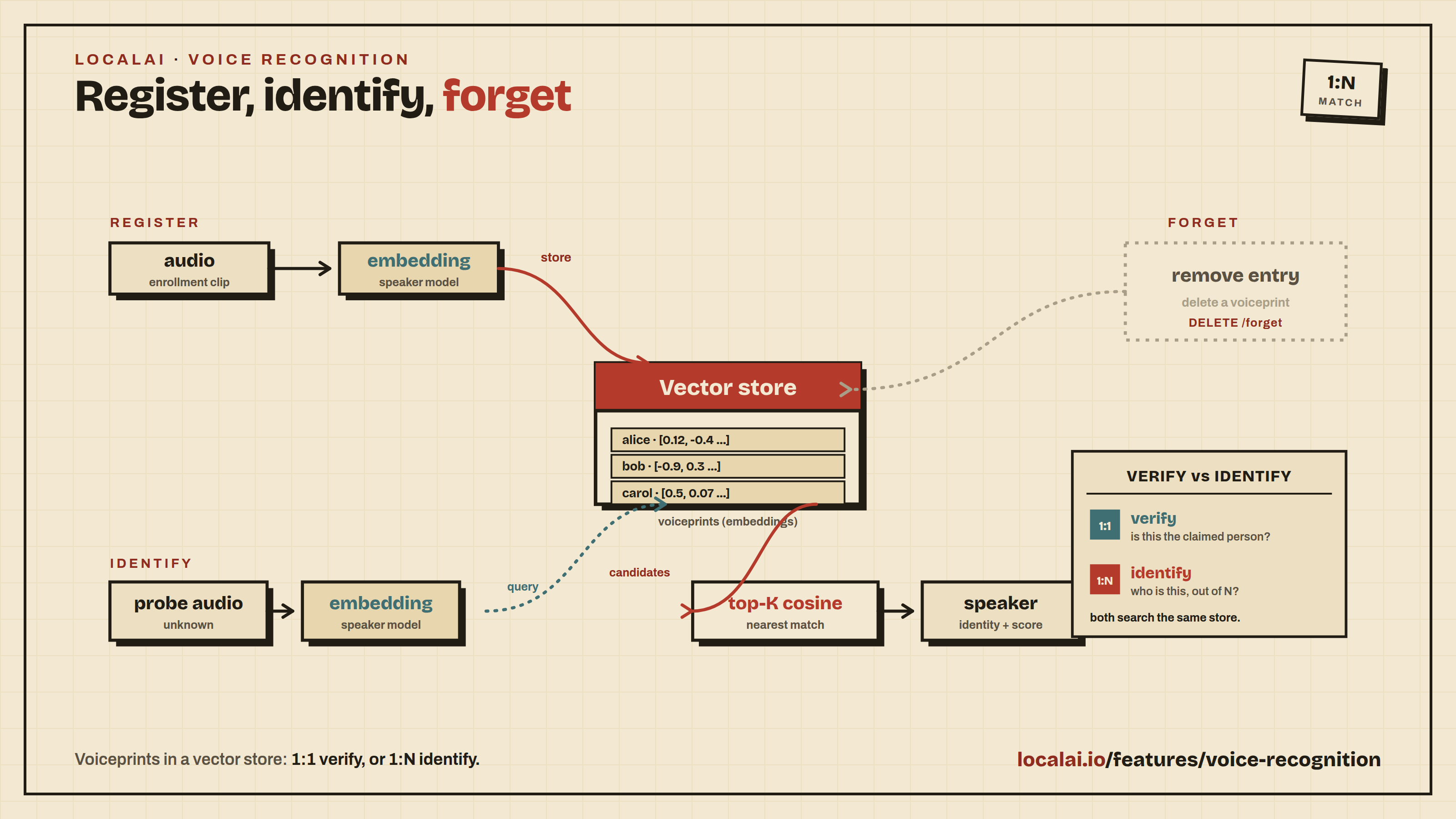
1:N identification workflow (register → identify → forget)
Same flow as face recognition, same in-memory vector store under the hood.
Register known speakers:
Identify an unknown probe:
Remove a speaker by ID:
Warning
Storage caveat. The default vector store is in-memory. All registered speakers are lost when LocalAI restarts. Persistent storage (pgvector) is a tracked future enhancement shared with face recognition - the voice-recognition HTTP API is designed to swap the backing store without changing the wire format.
API reference
POST /v1/voice/verify (1:1)
| field | type | description |
|---|---|---|
model | string | gallery entry name (e.g. speechbrain-ecapa-tdnn) |
audio1, audio2 | string | URL, base64, or data-URI of an audio file |
threshold | float, optional | cosine-distance cutoff; default 0.25 for ECAPA-TDNN |
anti_spoofing | bool, optional | reserved - unused in the current release |
Returns verified, distance, threshold, confidence, model,
and processing_time_ms.
POST /v1/voice/analyze
Returns demographic attributes (age, gender, emotion) inferred from speech:
| field | type | description |
|---|---|---|
model | string | gallery entry |
audio | string | URL / base64 / data-URI |
actions | string[] | subset of ["age","gender","emotion"]; empty = all supported |
Emotion is inferred from the SUPERB emotion-recognition checkpoint
(superb/wav2vec2-base-superb-er, Apache 2.0) - 4-way categorical
neutral / happy / angry / sad. The model auto-downloads on the first
analyze call.
Age and gender are opt-in: no standard-transformers checkpoint
with a clean classifier head is shipped as the default. The
high-accuracy Audeering age/gender model uses a custom multi-task
head that AutoModelForAudioClassification doesn’t load safely
(the age weights are silently dropped and the classifier is
re-initialised with random values). To enable age/gender, set
age_gender_model:<repo> in the model YAML’s options: pointing at
a checkpoint with a vanilla Wav2Vec2ForSequenceClassification
head. Override the emotion default similarly via emotion_model:.
Set either to an empty string to disable that head.
If a head fails to load (offline, disk full, transformers
missing), the engine degrades gracefully: it still returns the
attributes it could compute. When nothing can be computed the backend
returns 501 Unimplemented.
Analyze is supported by both speechbrain-ecapa-tdnn and
wespeaker-resnet34 - the speaker recognizer and the analysis head
are independent.
POST /v1/voice/register (1:N enrollment)
| field | type | description |
|---|---|---|
model | string | voice recognition model |
audio | string | speaker audio to enroll |
name | string | human-readable label |
labels | map[string]string, optional | arbitrary metadata |
store | string, optional | vector store model; defaults to local-store |
Returns {id, name, registered_at}. The id is an opaque UUID used
by /v1/voice/identify and /v1/voice/forget.
POST /v1/voice/identify (1:N recognition)
| field | type | description |
|---|---|---|
model | string | voice recognition model |
audio | string | probe audio |
top_k | int, optional | max matches to return; default 5 |
threshold | float, optional | cosine-distance cutoff; default 0.25 |
store | string, optional | vector store model |
Returns a list of matches sorted by ascending distance, each with
id, name, labels, distance, confidence, and match
(distance ≤ threshold).
POST /v1/voice/forget
| field | type | description |
|---|---|---|
id | string | ID returned by /v1/voice/register |
Returns 204 No Content on success, 404 Not Found if the ID is
unknown.
POST /v1/voice/embed
Returns the L2-normalized speaker embedding vector.
| field | type | description |
|---|---|---|
model | string | voice model |
audio | string | URL / base64 / data-URI |
Returns {embedding: float[], dim: int, model: string}. Dimension
depends on the recognizer: 192 for ECAPA-TDNN, 256 for WeSpeaker
ResNet34.
Note: the OpenAI-compatible
/v1/embeddingsendpoint is intentionally text-only - it does nothing useful with audio input. Use/v1/voice/embedfor audio.
Audio input
Audio is materialised by the HTTP layer to a temporary WAV file before the gRPC call. All audio fields accept:
http:///https://URLs (downloaded server-side, subject toValidateExternalURLsafety checks).- Raw base64 (no prefix).
- Data URIs (
data:audio/wav;base64,...).
The backend itself always receives a filesystem path - the same convention the Whisper / Voxtral transcription backends use.
Threshold reference
| Recognizer | Cosine-distance threshold |
|---|---|
| ECAPA-TDNN (SpeechBrain, VoxCeleb) | ~0.25 |
| WeSpeaker ResNet34 | ~0.30 |
| 3D-Speaker ERes2Net | ~0.28 |
Pass threshold explicitly when switching recognizers - the per-model
default only applies when omitted.
Related features
- Face Recognition - the image analog; the two share a registry design.
- Audio to Text - transcription (Whisper, Voxtral, faster-whisper). Runs in addition to, not instead of, voice recognition.
- Stores - the generic vector store powering both the face and voice 1:N recognition pipelines.
- Embeddings - text-only OpenAI-compatible
embedding endpoint; for audio embeddings use
/v1/voice/embed.