Setting Up Models
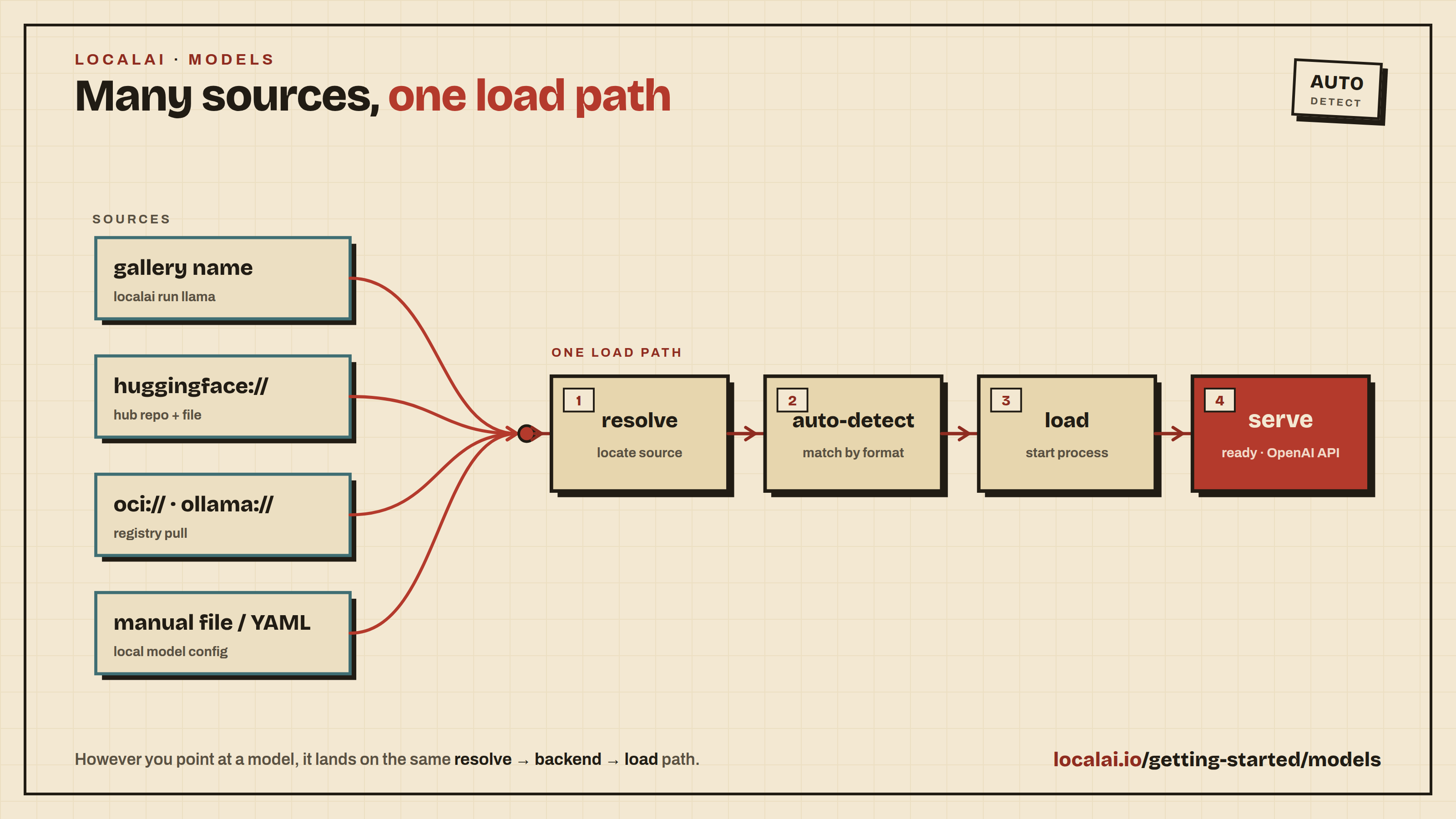
This section covers everything you need to know about installing and configuring models in LocalAI. You’ll learn multiple methods to get models running.
Prerequisites
- LocalAI installed and running (see Quickstart if you haven’t set it up yet)
- Basic understanding of command line usage
Method 1: Using the Model Gallery (Easiest)
The Model Gallery is the simplest way to install models. It provides pre-configured models ready to use.
Via WebUI
- Open the LocalAI WebUI at
http://localhost:8080 - Navigate to the “Models” tab
- Browse available models
- Click “Install” on any model you want
- Wait for installation to complete
For more details, refer to the Gallery Documentation.
Via CLI
To run models available in the LocalAI gallery, you can use the model name as the URI. For example, to run LocalAI with the Hermes model, execute:
To install only the model, use:
Note: The galleries available in LocalAI can be customized to point to a different URL or a local directory. For more information on how to setup your own gallery, see the Gallery Documentation.
Browse Online
Visit models.localai.io to browse all available models in your browser.
Method 1.5: Import Models via WebUI
The WebUI provides a powerful model import interface that supports both simple and advanced configuration:
Simple Import Mode
- Open the LocalAI WebUI at
http://localhost:8080 - Click “Import Model”
- Enter the model URI (e.g.,
https://huggingface.co/Qwen/Qwen3-VL-8B-Instruct-GGUF) - Optionally configure preferences:
- Backend selection
- Model name
- Description
- Quantizations
- Embeddings support
- Custom preferences
- Click “Import Model” to start the import process
Advanced Import Mode
For full control over model configuration:
- In the WebUI, click “Import Model”
- Toggle to “Advanced Mode”
- Edit the YAML configuration directly in the code editor
- Use the “Validate” button to check your configuration
- Click “Create” or “Update” to save
The advanced editor includes:
- Syntax highlighting
- YAML validation
- Format and copy tools
- Full configuration options
This is especially useful for:
- Custom model configurations
- Fine-tuning model parameters
- Setting up complex model setups
- Editing existing model configurations
Method 2: Installing from Hugging Face
LocalAI can directly install models from Hugging Face:
The format is: huggingface://<repository>/<model-file> (
Examples
Method 3: Installing from OCI Registries
Ollama Registry
Standard OCI Registry
Note
When pulling models from Ollama or OCI registries, LocalAI identifies itself with a LocalAI/<version> User-Agent header so registry operators can attribute usage to LocalAI.
Run Models via URI
To run models via URI, specify a URI to a model file or a configuration file when starting LocalAI. Valid syntax includes:
file://path/to/model(absolute path to a file within your models directory)huggingface://repository_id/model_file(e.g.,huggingface://TheBloke/phi-2-GGUF/phi-2.Q8_0.gguf)- From OCIs:
oci://container_image:tag,ollama://model_id:tag - From configuration files:
https://gist.githubusercontent.com/.../phi-2.yaml
Note
When using file:// URLs, the path must point to a file within your models directory (specified by MODELS_PATH). Files outside this directory are rejected for security reasons.
Configuration files can be used to customize the model defaults and settings. For advanced configurations, refer to the Customize Models section.
Examples
Method 4: Manual Installation
For full control, you can manually download and configure models.
Step 1: Download a Model
Download a GGUF model file. Popular sources:
Example:
Step 2: Create a Configuration File (Optional)
Create a YAML file to configure the model:
Customize model defaults and settings with a configuration file. For advanced configurations, refer to the Advanced Documentation.
Step 3: Run LocalAI
Choose one of the following methods to run LocalAI:
Tip
Other Docker Images:
For other Docker images, please refer to the table in the container images section.
Example:
Note
- If running on Apple Silicon (ARM), it is not recommended to run on Docker due to emulation. Follow the build instructions to use Metal acceleration for full GPU support.
- If you are running on Apple x86_64, you can use Docker without additional gain from building it from source.
Tip
Other Docker Images:
For other Docker images, please refer to the table in Getting Started.
Note: If you are on Windows, ensure the project is on the Linux filesystem to avoid slow model loading. For more information, see the Microsoft Docs.
For Kubernetes deployment, see the Kubernetes installation guide.
LocalAI binary releases are available on GitHub.
Tip
If installing on macOS, you might encounter a message saying:
“local-ai-git-Darwin-arm64” (or the name you gave the binary) can’t be opened because Apple cannot check it for malicious software.
Hit OK, then go to Settings > Privacy & Security > Security and look for the message:
“local-ai-git-Darwin-arm64” was blocked from use because it is not from an identified developer.
Press “Allow Anyway.”
For instructions on building LocalAI from source, see the Build from Source guide.
GPU Acceleration
For instructions on GPU acceleration, visit the GPU Acceleration page.
For more model configurations, visit the Examples Section.
Understanding Model Files
File Formats
- GGUF: Modern format, recommended for most use cases
- GGML: Older format, still supported but deprecated
Quantization Levels
Models come in different quantization levels (quality vs. size trade-off):
| Quantization | Size | Quality | Use Case |
|---|---|---|---|
| Q8_0 | Largest | Highest | Best quality, requires more RAM |
| Q6_K | Large | Very High | High quality |
| Q4_K_M | Medium | High | Balanced (recommended) |
| Q4_K_S | Small | Medium | Lower RAM usage |
| Q2_K | Smallest | Lower | Minimal RAM, lower quality |
Choosing the Right Model
Consider:
- RAM available: Larger models need more RAM
- Use case: Different models excel at different tasks
- Speed: Smaller quantizations are faster
- Quality: Higher quantizations produce better output
Model Configuration
Basic Configuration
Create a YAML file in your models directory:
Advanced Configuration
See the Model Configuration guide for all available options.
Managing Models
List Installed Models
Remove Models
Simply delete the model file and configuration from your models directory:
Troubleshooting
Model Not Loading
Check backend: Ensure the required backend is installed
Check logs: Enable debug mode
Verify file: Ensure the model file is not corrupted
Out of Memory
- Use a smaller quantization (Q4_K_S or Q2_K)
- Reduce
context_sizein configuration - Close other applications to free RAM
Wrong Backend
Check the Compatibility Table to ensure you’re using the correct backend for your model.
Best Practices
- Start small: Begin with smaller models to test your setup
- Use quantized models: Q4_K_M is a good balance for most use cases
- Organize models: Keep your models directory organized
- Backup configurations: Save your YAML configurations
- Monitor resources: Watch RAM and disk usage